
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- conda 기초 설정
- 3000 port kill
- conda base 활성화
- window netstat time wait 제거
- time wait port kill
- 실행중인 포트 죽이기
- conda 가상환경 설정 오류
- 오블완
- 려려
- 티스토리챌린지
- conda base 기본 설정
- Today
- Total
모도리는 공부중
21.03.05. 딥러닝 - 동물 이미지 인식, 패션 이미지 분류 본문
21.03.05. 딥러닝 - 동물 이미지 인식, 패션 이미지 분류
공부하는 모도리 2021. 3. 5. 17:56개, 고양이, 말 이미지 인식 - 개, 고양이를 학습했던 모델을 그대로 활용
오늘 수업 실습에 앞서서 먼저 어제 진행했던 파일을 복제하여 사용한다. 복제하는 방법은 그림으로 첨부.

그리고 동물이미지를 구하기 위해 아래의 캐글 사이트를 접속한다.
www.kaggle.com/alessiocorrado99/animals10
Animals-10
Animal pictures of 10 different categories taken from google images
www.kaggle.com
폴더명이 이태리어로 되어있다보니 '말' 폴더명이 horse가 아니고 cavallo로 되어있다. 폴더를 찾아서 열면 다음과 같이 이름이 제각기(물론 규칙이 있겠지만)로 되어있으니 사용 편의성을 위해 파일을 전체선택(ctrl+A)해서 f2를 누르고 horse를 입력하여 한 번에 이름을 바꿔주도록 한다.

이 기능을 몰랐어서... 감탄하고 있었는데...

import os
base_dir = "./data/dogs_vs_cats_small2_2"
train_dir = os.path.join(base_dir, "train")
test_dir = os.path.join(base_dir, "test")
validation_dir = os.path.join(base_dir, "validation")
train_cats_dir = os.path.join(train_dir, "cats")
train_dogs_dir = os.path.join(train_dir, "dogs")
train_horses_dir = os.path.join(train_dir, "horses")
test_cats_dir = os.path.join(test_dir, "cats")
test_dogs_dir = os.path.join(test_dir, "dogs")
validation_cats_dir = os.path.join(validation_dir, "cats")
validation_dogs_dir = os.path.join(validation_dir, "dogs")
validation_horses_dir = os.path.join(validation_dir, "horses")
# 각 폴더에 있는 파일의 개수를 출력
print("훈련용 고양이 데이터 개수 : ", len(os.listdir(train_cats_dir)))
print("훈련용 개 데이터 개수 : ", len(os.listdir(train_dogs_dir)))
print("훈련용 말 데이터 개수 : ", len(os.listdir(train_horses_dir)))
print("테스트용 고양이 데이터 개수 : ", len(os.listdir(test_cats_dir)))
print("테스트용 개 데이터 개수 : ", len(os.listdir(test_dogs_dir)))
print("검증용 고양이 데이터 개수 : ", len(os.listdir(validation_cats_dir)))
print("검증용 개 데이터 개수 : ", len(os.listdir(validation_dogs_dir)))
print("검증용 말 데이터 개수 : ", len(os.listdir(validation_horses_dir)))out :
훈련용 고양이 데이터 개수 : 1000
훈련용 개 데이터 개수 : 1000
훈련용 말 데이터 개수 : 1000
테스트용 고양이 데이터 개수 : 11
테스트용 개 데이터 개수 : 11
검증용 고양이 데이터 개수 : 500
검증용 개 데이터 개수 : 500
검증용 말 데이터 개수 : 500
horses까지 추가되어 총 3개가 되었으니 이진분류가 아닌 다중분류에 속한다. 고로, 더이상 binary가 아니라 categorical이다.
# 이미지 처리용 라이브러리
from tensorflow.keras.preprocessing.image import ImageDataGenerator # 전처리
# 0~1 사이값으로 픽셀값을 변환
train_datagen = ImageDataGenerator(rescale=1./255)
test_datagen = ImageDataGenerator(rescale=1./255)
# 이미지 전처리
# 폴더에 있는 이미지를 전처리
train_generator = train_datagen.flow_from_directory(
# 폴더명
train_dir,
# 이미지 크기를 동일한 크기로 변환
target_size = (150, 150),
# 한 번에 전처리할 이미지의 수
batch_size = 20,
# 라벨링 : binary 이진라벨링, categorical 다중라벨링
# 라벨링 방법 : 폴더명의 첫 문자의 알파벳으로 0부터 부여
class_mode = "categorical"
)
test_generator = test_datagen.flow_from_directory(
# 폴더명
validation_dir,
# 이미지 크기를 동일한 크기로 변환
target_size = (150, 150),
# 한 번에 전처리할 이미지의 수
batch_size = 20,
# 라벨링 : binary 이진라벨링, categorical 다중라벨링
# 라벨링 방법 : 폴더명의 첫 문자의 알파벳으로 0부터 부여
class_mode = "categorical"
)out :
Found 3000 images belonging to 3 classes.
Found 1500 images belonging to 3 classes.
print(train_generator.class_indices)
print(test_generator.class_indices)out :
{'cats': 0, 'dogs': 1, 'horses': 2}
{'cats': 0, 'dogs': 1, 'horses': 2}
activation도 sigmoid가 아닌 softmax로 변경
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Flatten
from tensorflow.keras.layers import Conv2D, MaxPooling2D
model1 = Sequential()
model1.add(Conv2D(filters=32, kernel_size=(3, 3), input_shape=(150, 150, 3), padding="same", activation="relu"))
model1.add(MaxPooling2D(pool_size=(2, 2)))
model1.add(Conv2D(filters=64, kernel_size=(3, 3), input_shape=(150, 150, 3), padding="same", activation="relu"))
model1.add(MaxPooling2D(pool_size=(2, 2)))
model1.add(Conv2D(filters=128, kernel_size=(3, 3), input_shape=(150, 150, 3), padding="same", activation="relu"))
model1.add(MaxPooling2D(pool_size=(2, 2)))
model1.add(Conv2D(filters=256, kernel_size=(3, 3), input_shape=(150, 150, 3), padding="same", activation="relu"))
model1.add(MaxPooling2D(pool_size=(2, 2)))
model1.add(Flatten())
model1.add(Dense(units=512, activation="relu"))
model1.add(Dropout(0.5))
model1.add(Dense(units=3, activation="softmax"))
model1.summary()out :
| Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d (Conv2D) (None, 150, 150, 32) 896 _________________________________________________________________ max_pooling2d (MaxPooling2D) (None, 75, 75, 32) 0 _________________________________________________________________ conv2d_1 (Conv2D) (None, 75, 75, 64) 18496 _________________________________________________________________ max_pooling2d_1 (MaxPooling2 (None, 37, 37, 64) 0 _________________________________________________________________ conv2d_2 (Conv2D) (None, 37, 37, 128) 73856 _________________________________________________________________ max_pooling2d_2 (MaxPooling2 (None, 18, 18, 128) 0 _________________________________________________________________ conv2d_3 (Conv2D) (None, 18, 18, 256) 295168 _________________________________________________________________ max_pooling2d_3 (MaxPooling2 (None, 9, 9, 256) 0 _________________________________________________________________ flatten (Flatten) (None, 20736) 0 _________________________________________________________________ dense (Dense) (None, 512) 10617344 _________________________________________________________________ dropout (Dropout) (None, 512) 0 _________________________________________________________________ dense_1 (Dense) (None, 3) 1539 ================================================================= Total params: 11,007,299 Trainable params: 11,007,299 Non-trainable params: 0 _________________________________________________________________ |
loss도 마찬가지. categorical_crossentropy로 바꾸어준다.
model1.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["acc"])
# generator : 제너레이터를 설정
h1 = model1.fit_generator(generator=train_generator, epochs=30, validation_data=test_generator)out :
WARNING:tensorflow:From <ipython-input-7-1bb476a2e5e2>:2: Model.fit_generator (from tensorflow.python.keras.engine.training) is deprecated and will be removed in a future version.
Instructions for updating:
Please use Model.fit, which supports generators.
WARNING:tensorflow:sample_weight modes were coerced from
...
to
['...']
WARNING:tensorflow:sample_weight modes were coerced from
...
to
['...']
Train for 150 steps, validate for 75 steps
Epoch 1/30
150/150 [==============================] - 11s 75ms/step - loss: 0.9633 - acc: 0.4940 - val_loss: 0.8663 - val_acc: 0.6153
Epoch 2/30
150/150 [==============================] - 8s 51ms/step - loss: 0.7579 - acc: 0.6187 - val_loss: 0.6845 - val_acc: 0.6680
Epoch 3/30
150/150 [==============================] - 8s 51ms/step - loss: 0.6645 - acc: 0.6757 - val_loss: 0.6437 - val_acc: 0.7060
Epoch 4/30
150/150 [==============================] - 8s 51ms/step - loss: 0.6045 - acc: 0.7153 - val_loss: 0.6338 - val_acc: 0.7127
Epoch 5/30
150/150 [==============================] - 8s 51ms/step - loss: 0.5231 - acc: 0.7633 - val_loss: 0.6068 - val_acc: 0.7247
Epoch 6/30
150/150 [==============================] - 8s 51ms/step - loss: 0.4727 - acc: 0.7883 - val_loss: 0.7154 - val_acc: 0.6720
Epoch 7/30
150/150 [==============================] - 8s 52ms/step - loss: 0.4041 - acc: 0.8280 - val_loss: 0.6553 - val_acc: 0.7500
Epoch 8/30
150/150 [==============================] - 8s 52ms/step - loss: 0.3323 - acc: 0.8630 - val_loss: 0.6299 - val_acc: 0.7460
Epoch 9/30
150/150 [==============================] - 8s 52ms/step - loss: 0.2645 - acc: 0.8943 - val_loss: 0.7078 - val_acc: 0.7653
Epoch 10/30
150/150 [==============================] - 8s 52ms/step - loss: 0.2265 - acc: 0.9123 - val_loss: 0.7124 - val_acc: 0.7480
Epoch 11/30
150/150 [==============================] - 8s 52ms/step - loss: 0.1641 - acc: 0.9337 - val_loss: 0.7786 - val_acc: 0.7567
Epoch 12/30
150/150 [==============================] - 8s 52ms/step - loss: 0.1481 - acc: 0.9433 - val_loss: 0.8521 - val_acc: 0.7453
Epoch 13/30
150/150 [==============================] - 8s 52ms/step - loss: 0.1203 - acc: 0.9553 - val_loss: 0.9640 - val_acc: 0.7680
Epoch 14/30
150/150 [==============================] - 8s 52ms/step - loss: 0.1053 - acc: 0.9630 - val_loss: 0.9989 - val_acc: 0.7107
Epoch 15/30
150/150 [==============================] - 8s 52ms/step - loss: 0.0816 - acc: 0.9717 - val_loss: 1.1470 - val_acc: 0.7427
Epoch 16/30
150/150 [==============================] - 8s 51ms/step - loss: 0.0587 - acc: 0.9783 - val_loss: 1.1178 - val_acc: 0.7487
Epoch 17/30
150/150 [==============================] - 8s 52ms/step - loss: 0.0525 - acc: 0.9787 - val_loss: 1.3174 - val_acc: 0.7480
Epoch 18/30
150/150 [==============================] - 8s 52ms/step - loss: 0.0571 - acc: 0.9800 - val_loss: 1.2667 - val_acc: 0.7487
Epoch 19/30
150/150 [==============================] - 8s 52ms/step - loss: 0.0488 - acc: 0.9783 - val_loss: 1.5896 - val_acc: 0.7373
Epoch 20/30
150/150 [==============================] - 8s 52ms/step - loss: 0.0561 - acc: 0.9817 - val_loss: 1.4970 - val_acc: 0.7280
Epoch 21/30
150/150 [==============================] - 8s 52ms/step - loss: 0.0267 - acc: 0.9923 - val_loss: 1.5404 - val_acc: 0.7487
Epoch 22/30
150/150 [==============================] - 8s 52ms/step - loss: 0.0483 - acc: 0.9857 - val_loss: 1.5844 - val_acc: 0.7633
Epoch 23/30
150/150 [==============================] - 8s 52ms/step - loss: 0.0288 - acc: 0.9920 - val_loss: 1.6528 - val_acc: 0.7573
Epoch 24/30
150/150 [==============================] - 8s 52ms/step - loss: 0.0094 - acc: 0.9977 - val_loss: 1.8498 - val_acc: 0.7553
Epoch 25/30
150/150 [==============================] - 8s 52ms/step - loss: 0.0821 - acc: 0.9760 - val_loss: 1.7805 - val_acc: 0.7307
Epoch 26/30
150/150 [==============================] - 8s 51ms/step - loss: 0.0360 - acc: 0.9880 - val_loss: 1.6722 - val_acc: 0.7527
Epoch 27/30
150/150 [==============================] - 8s 51ms/step - loss: 0.0782 - acc: 0.9770 - val_loss: 1.3163 - val_acc: 0.7320
Epoch 28/30
150/150 [==============================] - 8s 52ms/step - loss: 0.0357 - acc: 0.9883 - val_loss: 1.4310 - val_acc: 0.7627
Epoch 29/30
150/150 [==============================] - 8s 52ms/step - loss: 0.0059 - acc: 0.9983 - val_loss: 1.5812 - val_acc: 0.7540
Epoch 30/30
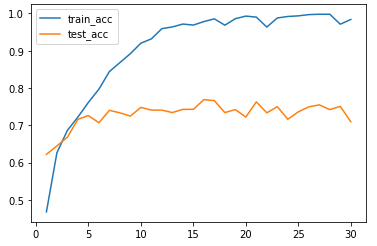
150/150 [==============================] - 8s 52ms/step - loss: 0.0201 - acc: 0.9957 - val_loss: 1.6541 - val_acc: 0.7320import matplotlib.pyplot as plt
acc = h1.history["acc"]
val_acc = h1.history["val_acc"]
plt.plot(range(1, len(acc)+1), acc, label="train_acc")
plt.plot(range(1, len(acc)+1), val_acc, label="test_acc")
plt.legend()out :
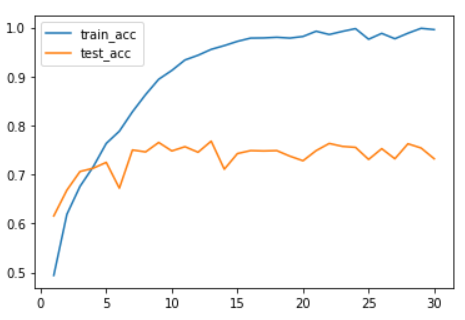
우리반 사람들도 대개 비슷한 그래프 형태를 보였다.



증식은 생략하고 전이학습으로 넘어간다.
from tensorflow.keras.applications import VGG16
# weights : 초기화할 가중치
# include_top = False : 분류기(Dense)를 빼고 Conv레이어만 사용하겠다.
# - True로 두면 Dense층이 추가된다
# input_shape : VGG16에 넣어줄 입력 크기
conv_base = VGG16(weights="imagenet", include_top = False, input_shape=(150, 150, 3))
conv_base.summary()out :
| Model: "vgg16" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_1 (InputLayer) [(None, 150, 150, 3)] 0 _________________________________________________________________ block1_conv1 (Conv2D) (None, 150, 150, 64) 1792 _________________________________________________________________ block1_conv2 (Conv2D) (None, 150, 150, 64) 36928 _________________________________________________________________ block1_pool (MaxPooling2D) (None, 75, 75, 64) 0 _________________________________________________________________ block2_conv1 (Conv2D) (None, 75, 75, 128) 73856 _________________________________________________________________ block2_conv2 (Conv2D) (None, 75, 75, 128) 147584 _________________________________________________________________ block2_pool (MaxPooling2D) (None, 37, 37, 128) 0 _________________________________________________________________ block3_conv1 (Conv2D) (None, 37, 37, 256) 295168 _________________________________________________________________ block3_conv2 (Conv2D) (None, 37, 37, 256) 590080 _________________________________________________________________ block3_conv3 (Conv2D) (None, 37, 37, 256) 590080 _________________________________________________________________ block3_pool (MaxPooling2D) (None, 18, 18, 256) 0 _________________________________________________________________ block4_conv1 (Conv2D) (None, 18, 18, 512) 1180160 _________________________________________________________________ block4_conv2 (Conv2D) (None, 18, 18, 512) 2359808 _________________________________________________________________ block4_conv3 (Conv2D) (None, 18, 18, 512) 2359808 _________________________________________________________________ block4_pool (MaxPooling2D) (None, 9, 9, 512) 0 _________________________________________________________________ block5_conv1 (Conv2D) (None, 9, 9, 512) 2359808 _________________________________________________________________ block5_conv2 (Conv2D) (None, 9, 9, 512) 2359808 _________________________________________________________________ block5_conv3 (Conv2D) (None, 9, 9, 512) 2359808 _________________________________________________________________ block5_pool (MaxPooling2D) (None, 4, 4, 512) 0 ================================================================= Total params: 14,714,688 Trainable params: 14,714,688 Non-trainable params: 0 _________________________________________________________________ |
import os
import os.path
import numpy as np
from tensorflow.keras.preprocessing.image import ImageDataGenerator
base_dir = "./data/dogs_vs_cats_small2_2"
train_dir = os.path.join(base_dir, "train")
test_dir = os.path.join(base_dir, "test")
validation_dir = os.path.join(base_dir, "validation")
dataGen = ImageDataGenerator(rescale=1./255)
batch_size = 20
# VGG16에 개고양이 이미지를 입력하고 특성을 추출하여 특성맵을 받는 함수
# 이미지가 있는 폴더명, 폴더에 있는 이미지의 수
def extract_feature(directory, sample_count):
# VGG16으로부터 받은 특성맵을 저장할 리스트
# 4, 4, 512 : VGG16의 출력크기
features = np.zeros(shape=(sample_count, 4, 4, 512))
# 각 이미지의 라벨을 저장하기 위한 리스트
labels = np.zeros(shape=(sample_count))
# VGG16으로 이미지를 전달하기 위한 제너레이터를 설정
generator = dataGen.flow_from_directory(directory,
target_size=(150, 150),
batch_size=batch_size,
class_mode="sparse")
# VGG16호출 횟수를 카운트
i = 0
# 폴더에 있는 전체 이미지를 VGG16으로 batch_size 개수만큼씩 전달
# generator로부터 변환된 이미지와 라벨을 20개씩 받는다
for inputs_batch, labels_batch in generator:
# VGG16에 이미지(input_batch)입력으로 주어 특성맵을 받아온다
features_batch = conv_base.predict(inputs_batch)
# features리스트에 20개씩 특성맵을 추가
features[i*batch_size : (i+1)*batch_size] = features_batch
labels[i*batch_size : (i+1)*batch_size] = labels_batch
i = i+1
# 폴더에 있는 이미지수(sample_count)를 (sample_count)만큼 다 처리했다면
if i*batch_size >= sample_count:
braek
return features, labels# trian, validation 폴더에 있는 이미지를 VGG16에 전송해서 특성맵을 추출
train_features, train_labels = extract_feature(train_dir, 3000)
validation_features, validation_labels = extract_feature(validation_dir, 1500)out :
Found 3000 images belonging to 3 classes.
Found 1500 images belonging to 3 classes.
# VGG16에서 넘어온 특성맵이 3차원 데이터이므로 1차원으로 변환
train_features = np.reshape(train_features, (3000, 4*4*512))
validation_features = np.reshape(validation_features, (1500, 4*4*512))
train_features.shape, validation_features.shapeout : ((3000, 8192), (1500, 8192))
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout
model4 = Sequential()
model4.add(Dense(256, input_dim=train_features.shape[1], activation="relu"))
model4.add(Dropout(0.5))
model4.add(Dense(3, activation="softmax"))
model4.summary()out :
| Model: "sequential_1" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= dense_2 (Dense) (None, 256) 2097408 _________________________________________________________________ dropout_1 (Dropout) (None, 256) 0 _________________________________________________________________ dense_3 (Dense) (None, 3) 771 ================================================================= Total params: 2,098,179 Trainable params: 2,098,179 Non-trainable params: 0 _________________________________________________________________ |
model4.compile(loss="sparse_categorical_crossentropy", optimizer="RMSprop", metrics=["acc"])
h4 = model4.fit(train_features, train_labels, epochs=30, batch_size=20, validation_data=(validation_features, validation_labels))out :
| Train on 3000 samples, validate on 1500 samples Epoch 1/30 3000/3000 [==============================] - 1s 283us/sample - loss: 0.5582 - acc: 0.9957 - val_loss: 0.1333 - val_acc: 0.9907 Epoch 2/30 3000/3000 [==============================] - 1s 178us/sample - loss: 0.0497 - acc: 0.9970 - val_loss: 0.0369 - val_acc: 0.9907 Epoch 3/30 3000/3000 [==============================] - 1s 179us/sample - loss: 0.0176 - acc: 0.9980 - val_loss: 0.0269 - val_acc: 0.9927 Epoch 4/30 3000/3000 [==============================] - 1s 183us/sample - loss: 0.0159 - acc: 0.9980 - val_loss: 0.0275 - val_acc: 0.9907 Epoch 5/30 3000/3000 [==============================] - 1s 196us/sample - loss: 0.0316 - acc: 0.9967 - val_loss: 0.0481 - val_acc: 0.9900 Epoch 6/30 3000/3000 [==============================] - 1s 201us/sample - loss: 0.0098 - acc: 0.9983 - val_loss: 0.0098 - val_acc: 0.9967 Epoch 7/30 3000/3000 [==============================] - 1s 196us/sample - loss: 0.0119 - acc: 0.9983 - val_loss: 0.0241 - val_acc: 0.9960 Epoch 8/30 3000/3000 [==============================] - 1s 183us/sample - loss: 0.0126 - acc: 0.9977 - val_loss: 0.0361 - val_acc: 0.9927 Epoch 9/30 3000/3000 [==============================] - 1s 180us/sample - loss: 0.0040 - acc: 0.9983 - val_loss: 0.0087 - val_acc: 0.9960 Epoch 10/30 3000/3000 [==============================] - 1s 194us/sample - loss: 0.0050 - acc: 0.9987 - val_loss: 0.0216 - val_acc: 0.9953 Epoch 11/30 3000/3000 [==============================] - 1s 176us/sample - loss: 0.0013 - acc: 0.9993 - val_loss: 0.0232 - val_acc: 0.9953 Epoch 12/30 3000/3000 [==============================] - 1s 181us/sample - loss: 1.3413e-05 - acc: 1.0000 - val_loss: 0.0377 - val_acc: 0.9953 Epoch 13/30 3000/3000 [==============================] - 1s 214us/sample - loss: 0.0066 - acc: 0.9990 - val_loss: 0.0095 - val_acc: 0.9967 Epoch 14/30 3000/3000 [==============================] - 1s 214us/sample - loss: 2.8784e-06 - acc: 1.0000 - val_loss: 0.0166 - val_acc: 0.9947 Epoch 15/30 3000/3000 [==============================] - 1s 205us/sample - loss: 2.6414e-04 - acc: 0.9997 - val_loss: 0.0459 - val_acc: 0.9953 Epoch 16/30 3000/3000 [==============================] - 1s 192us/sample - loss: 0.0017 - acc: 0.9997 - val_loss: 0.0230 - val_acc: 0.9967 Epoch 17/30 3000/3000 [==============================] - 1s 203us/sample - loss: 0.0044 - acc: 0.9993 - val_loss: 0.0207 - val_acc: 0.9973 Epoch 18/30 3000/3000 [==============================] - 1s 208us/sample - loss: 1.4602e-05 - acc: 1.0000 - val_loss: 0.0135 - val_acc: 0.9967 Epoch 19/30 3000/3000 [==============================] - 1s 186us/sample - loss: 1.0828e-04 - acc: 1.0000 - val_loss: 0.0232 - val_acc: 0.9940 Epoch 20/30 3000/3000 [==============================] - 1s 189us/sample - loss: 1.6643e-07 - acc: 1.0000 - val_loss: 0.0181 - val_acc: 0.9953 Epoch 21/30 3000/3000 [==============================] - 1s 186us/sample - loss: 0.0016 - acc: 0.9997 - val_loss: 0.0448 - val_acc: 0.9940 Epoch 22/30 3000/3000 [==============================] - 1s 169us/sample - loss: 1.8851e-05 - acc: 1.0000 - val_loss: 0.0186 - val_acc: 0.9947 Epoch 23/30 3000/3000 [==============================] - 1s 170us/sample - loss: 0.0050 - acc: 0.9997 - val_loss: 0.0275 - val_acc: 0.9940 Epoch 24/30 3000/3000 [==============================] - 1s 170us/sample - loss: 1.3818e-06 - acc: 1.0000 - val_loss: 0.0740 - val_acc: 0.9927 Epoch 25/30 3000/3000 [==============================] - 1s 170us/sample - loss: 8.2917e-05 - acc: 1.0000 - val_loss: 0.0305 - val_acc: 0.9960 Epoch 26/30 3000/3000 [==============================] - 1s 191us/sample - loss: 0.0026 - acc: 0.9997 - val_loss: 0.0244 - val_acc: 0.9953 Epoch 27/30 3000/3000 [==============================] - 1s 177us/sample - loss: 3.7972e-04 - acc: 0.9997 - val_loss: 0.0326 - val_acc: 0.9940 Epoch 28/30 3000/3000 [==============================] - 1s 190us/sample - loss: 0.0029 - acc: 0.9997 - val_loss: 0.0204 - val_acc: 0.9960 Epoch 29/30 3000/3000 [==============================] - 1s 167us/sample - loss: 3.1072e-06 - acc: 1.0000 - val_loss: 0.0206 - val_acc: 0.9967 Epoch 30/30 3000/3000 [==============================] - 1s 173us/sample - loss: 3.9011e-07 - acc: 1.0000 - val_loss: 0.0161 - val_acc: 0.9967 |
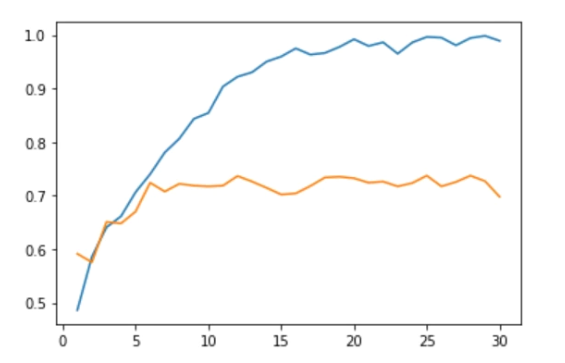
import matplotlib.pyplot as plt
acc = h4.history["acc"]
val_acc = h4.history["val_acc"]
plt.plot(range(1, len(acc)+1), acc, label="train_acc")
plt.plot(range(1, len(acc)+1), val_acc, label="test_acc")
plt.legend()out :

그래프 성능이 훨씬 좋아진 것을 확인할 수 있다.
패션이미지 분류
패션이미지 분류 학습을 위해 학습예제를 가져온다.
from tensorflow.keras.datasets import fashion_mnist
# 28x28 크기의 10가지 패션 흑백이미지 60,000개 훈련, 10,000개 테스트 데이터
(X_train, y_train), (X_test, y_test) = fashion_mnist.load_data()
X_train.shape, X_test.shape, y_train.shape, y_test.shapeout : ((60000, 28, 28), (10000, 28, 28), (60000,), (10000,))
import matplotlib.pyplot as plt
plt.imshow(X_train[0], cmap="gray")out :
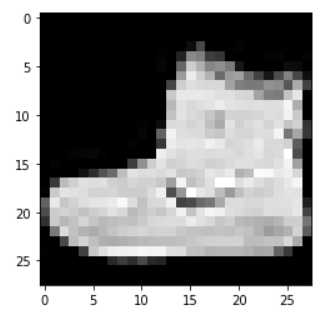
훈련데이터와 테스트데이터로 적당한 갯수인 1000개, 300개만 커팅해서 가져온다.
# 훈련 데이터 1000개, 테스트 데이터 300개만 자름
X_train = X_train[:1000, :]
y_train = y_train[:1000]
X_test = X_test[:300, :]
y_test = y_test[:300]
X_train.shape, X_test.shape, y_train.shape, y_test.shapeout : ((1000, 28, 28), (300, 28, 28), (1000,), (300,))
# y의 클래스가 몇 개인지 확인
import pandas as pd
pd.Series(y_train).unique()out : array([9, 0, 3, 2, 7, 5, 1, 6, 4, 8], dtype=uint8)
# 원핫 인코딩
from tensorflow.keras.utils import to_categorical
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
y_train.shape, y_test.shapeout : ((1000, 10), (300, 10))
28x28 이미지를 244x244 이미지로 크기를 변경
from PIL import Image
import numpy as np
train_resize_list = []
for i in range(len(X_train)):
# 배열로 되어있는 이미지를 이미지타입으로 바꿔서 크기를 변경
train_resize_image = Image.fromarray(X_train[i]).resize((244,244))
# 다시 학습데이터로 사용하기 위해 추가 (그냥은 들어가지 않으니 numpy배열로 변경)
train_resize_list.append(np.array(train_resize_image))
test_resize_list = []
for i in range(len(X_test)):
# 배열로 되어있는 이미지를 이미지타입으로 바꿔서 크기를 변경
test_resize_image = Image.fromarray(X_test[i]).resize((244,244))
# 다시 학습데이터로 사용하기 위해 추가 (그냥은 들어가지 않으니 numpy배열로 변경)
test_resize_list.append(np.array(test_resize_image))
# list를 배열로 변경
X_train_resized = np.array(train_resize_list)
X_test_resized = np.array(test_resize_list)
X_train_resized.shape, X_test_resized.shapeout : ((1000, 244, 244), (300, 244, 244))
이미지 사이즈를 변경해주었으니 출력해서 비교해본다. 먼저 리사이징 전 이미지는
plt.imshow(X_train[0], cmap="gray")
픽셀이 선명하게 보인다. 리사이징해준 이미지를 확인해보면
plt.imshow(X_train_resized[0], cmap="gray")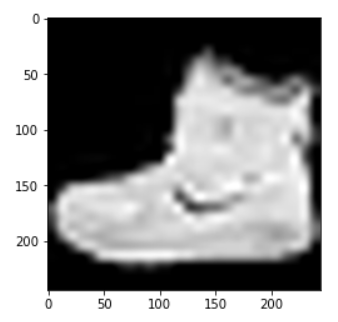
# 색상차원 추가
X_train_resized = X_train_resized.reshape(X_train_resized.shape[0], 244, 244, 1)
X_test_resized = X_test_resized.reshape(X_test_resized.shape[0], 244, 244, 1)
X_train_resized.shape, X_test_resized.shapeout : ((1000, 244, 244, 1), (300, 244, 244, 1))
# 훈련, 테스트 데이터로 분리
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X_train_resized, y_train, random_state=777)
X_train.shape, X_test.shape, y_train.shape, y_test.shapeout : ((750, 244, 244, 1), (250, 244, 244, 1), (750, 10), (250, 10))
신경망 학습
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout
from tensorflow.keras.layers import Flatten, Conv2D, MaxPooling2D
model1 = Sequential()
# filters와 kernel_size도 units처럼 생략하고 숫자만 작성해도 ok.
model1 = Sequential()
model1.add(Conv2D(32, (3,3), input_shape=(244, 244, 1),
activation="relu"))
model1.add(MaxPooling2D((2,2)))
model1.add(Conv2D(128, (3,3), activation="relu"))
model1.add(MaxPooling2D((2,2)))
model1.add(Conv2D(256, (3,3), activation="relu"))
model1.add(MaxPooling2D((2,2)))
model1.add(Conv2D(512, (3,3), activation="relu"))
model1.add(MaxPooling2D((2,2)))
model1.add(Flatten())
model1.add(Dense(512, activation='relu'))
model1.add(Dropout(0.5))
model1.add(Dense(10, activation='softmax'))
model1.summary()out :
| Model: "sequential_1" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d (Conv2D) (None, 242, 242, 32) 320 _________________________________________________________________ max_pooling2d (MaxPooling2D) (None, 121, 121, 32) 0 _________________________________________________________________ conv2d_1 (Conv2D) (None, 119, 119, 128) 36992 _________________________________________________________________ max_pooling2d_1 (MaxPooling2 (None, 59, 59, 128) 0 _________________________________________________________________ conv2d_2 (Conv2D) (None, 57, 57, 256) 295168 _________________________________________________________________ max_pooling2d_2 (MaxPooling2 (None, 28, 28, 256) 0 _________________________________________________________________ conv2d_3 (Conv2D) (None, 26, 26, 512) 1180160 _________________________________________________________________ max_pooling2d_3 (MaxPooling2 (None, 13, 13, 512) 0 _________________________________________________________________ flatten (Flatten) (None, 86528) 0 _________________________________________________________________ dense (Dense) (None, 512) 44302848 _________________________________________________________________ dropout (Dropout) (None, 512) 0 _________________________________________________________________ dense_1 (Dense) (None, 10) 5130 ================================================================= Total params: 45,820,618 Trainable params: 45,820,618 Non-trainable params: 0 _________________________________________________________________ |
model1.compile(loss="categorical_crossentropy",
optimizer="adam",
metrics = ["acc"])
h1 = model1.fit(X_train, y_train, epochs=20, batch_size=20,
validation_data=(X_test, y_test))out :
| Train on 750 samples, validate on 250 samples Epoch 1/20 750/750 [==============================] - 6s 8ms/sample - loss: 20.3453 - acc: 0.5893 - val_loss: 0.7260 - val_acc: 0.7800 Epoch 2/20 750/750 [==============================] - 2s 3ms/sample - loss: 0.6252 - acc: 0.7760 - val_loss: 0.6346 - val_acc: 0.8160 Epoch 3/20 750/750 [==============================] - 2s 3ms/sample - loss: 0.4563 - acc: 0.8387 - val_loss: 0.6568 - val_acc: 0.8000 Epoch 4/20 750/750 [==============================] - 2s 3ms/sample - loss: 0.3575 - acc: 0.8747 - val_loss: 0.6588 - val_acc: 0.8240 Epoch 5/20 750/750 [==============================] - 2s 3ms/sample - loss: 0.3150 - acc: 0.8973 - val_loss: 0.6725 - val_acc: 0.7920 Epoch 6/20 750/750 [==============================] - 2s 3ms/sample - loss: 0.2192 - acc: 0.9240 - val_loss: 0.7707 - val_acc: 0.8000 Epoch 7/20 750/750 [==============================] - 2s 3ms/sample - loss: 0.2292 - acc: 0.9307 - val_loss: 0.8896 - val_acc: 0.7840 Epoch 8/20 750/750 [==============================] - 2s 3ms/sample - loss: 0.1710 - acc: 0.9333 - val_loss: 0.9272 - val_acc: 0.7920 Epoch 9/20 750/750 [==============================] - 2s 3ms/sample - loss: 0.1500 - acc: 0.9493 - val_loss: 1.0057 - val_acc: 0.8000 Epoch 10/20 750/750 [==============================] - 2s 3ms/sample - loss: 0.1271 - acc: 0.9480 - val_loss: 0.8757 - val_acc: 0.7920 Epoch 11/20 750/750 [==============================] - 2s 3ms/sample - loss: 0.0993 - acc: 0.9613 - val_loss: 1.0343 - val_acc: 0.8160 Epoch 12/20 750/750 [==============================] - 2s 3ms/sample - loss: 0.0939 - acc: 0.9653 - val_loss: 1.0534 - val_acc: 0.8000 Epoch 13/20 750/750 [==============================] - 2s 3ms/sample - loss: 0.0871 - acc: 0.9733 - val_loss: 0.8950 - val_acc: 0.8240 Epoch 14/20 750/750 [==============================] - 2s 3ms/sample - loss: 0.0559 - acc: 0.9787 - val_loss: 1.0458 - val_acc: 0.8240 Epoch 15/20 750/750 [==============================] - 2s 3ms/sample - loss: 0.0639 - acc: 0.9773 - val_loss: 1.2778 - val_acc: 0.8240 Epoch 16/20 750/750 [==============================] - 2s 3ms/sample - loss: 0.0195 - acc: 0.9960 - val_loss: 1.5939 - val_acc: 0.8160 Epoch 17/20 750/750 [==============================] - 2s 3ms/sample - loss: 0.0377 - acc: 0.9840 - val_loss: 1.4754 - val_acc: 0.8120 Epoch 18/20 750/750 [==============================] - 2s 3ms/sample - loss: 0.0292 - acc: 0.9880 - val_loss: 1.4117 - val_acc: 0.8160 Epoch 19/20 750/750 [==============================] - 2s 3ms/sample - loss: 0.0589 - acc: 0.9760 - val_loss: 1.5752 - val_acc: 0.8000 Epoch 20/20 750/750 [==============================] - 2s 3ms/sample - loss: 0.0812 - acc: 0.9747 - val_loss: 1.3597 - val_acc: 0.7920 |
import matplotlib.pyplot as plt
acc = h1.history["acc"]
val_acc = h1.history["val_acc"]
plt.plot(range(1, len(acc)+1), acc, label="train")
plt.plot(range(1, len(acc)+1), val_acc, label="train")
plt.legend()out :

Xception 모델을 이용한 전이학습
from tensorflow.keras.datasets import fashion_mnist
# 28x28 크기의 10가지 패션 흑백이미지 60000개 훈련, 10000개 테스트 데이터
(X_train, y_train), (X_test, y_test) = fashion_mnist.load_data()
# 훈련 데이터 1000개, 테스트데이터 300개만 자름
X_train = X_train[:1000, :]
y_train = y_train[:1000,]
X_test = X_test[:300, :]
y_test = y_test[:300,]
# 원핫 인코딩
from tensorflow.keras.utils import to_categorical
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
y_train.shape, y_test.shapeout : (1000, 10), (300, 10))
from PIL import Image
import numpy as np
train_resize_list = []
for i in range(len(X_train)) :
# 배열된 이미지를 이미지타입으로 변경해서 크기를 변경
train_resize_image = Image.fromarray(X_train[i]).resize((244, 244))
# 다시 학습데이터로 쓰기위해 배열로 변경
train_resize_list.append(np.array(train_resize_image))
test_resize_list = []
for i in range(len(X_test)) :
# 배열된 이미지를 이미지타입으로 변경해서 크기를 변경
test_resize_image = Image.fromarray(X_test[i]).resize((244, 244))
# 다시 학습데이터로 쓰기위해 배열로 변경
test_resize_list.append(np.array(test_resize_image))
# list를 배열로 변경
X_train_resized = np.array(train_resize_list)
X_test_resized = np.array(test_resize_list)
X_train_resized.shape, X_test_resized.shapeout : ((1000, 244, 244), (300, 244, 244))
# 색상차원 추가
X_train_resized = X_train_resized.reshape(X_train_resized.shape[0],
244, 244, 1)
X_test_resized = X_test_resized.reshape(X_test_resized.shape[0],
244, 244, 1)
X_train_resized.shape, X_test_resized.shapeout : ((1000, 244, 244, 1), (300, 244, 244, 1))
# Xception에 입력으로 넣기 위해서 컬러이미지로 변경
import numpy as np
X_train_resized = np.repeat(X_train_resized, 3, axis=3) # 같은 것을 3개로 복사
X_test_resized = np.repeat(X_test_resized, 3, axis=3)
X_train_resized.shape, X_test_resized.shapeout : ((1000, 244, 244, 3), (300, 244, 244, 3))

위의 결과는 이 그림처럼 똑같은 것을 3장을 쌓은 형태이다.
from tensorflow.keras.applications import Xception
base_conv = Xception(weights="imagenet", include_top=False, input_shape=(244,244,3))
# 동결
base_conv.trainable = False
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Conv2D, MaxPooling2D, Flatten
model3 = Sequential()
model3.add(base_conv)
model3.add(Flatten())
model3.add(Dense(512, activation="relu"))
model3.add(Dense(10, activation="softmax"))
model3.summary()| Model: "sequential_2" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= xception (Model) (None, 8, 8, 2048) 20861480 _________________________________________________________________ flatten_1 (Flatten) (None, 131072) 0 _________________________________________________________________ dense_2 (Dense) (None, 512) 67109376 _________________________________________________________________ dense_3 (Dense) (None, 10) 5130 ================================================================= Total params: 87,975,986 Trainable params: 67,114,506 Non-trainable params: 20,861,480 _________________________________________________________________ |
model3.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["acc"])
model3.fit(X_train, y_train, epochs=20, batch_size=20, validation_data=(X_test, y_test))
오류 발생.. 눙물이 굴러간다. 또르륵. 또르르륵.
'K-디지털 빅데이터 분석서비스 개발자과정 20.11.02~21.04.12 > PYTHON(웹크롤링, 머신·딥러닝)' 카테고리의 다른 글
| 21.03.09. 딥러닝 - RNN, LSTM, 단어 임베딩 (0) | 2021.03.09 |
|---|---|
| 21.03.08. 딥러닝 - RNN 단어 철자 예측 및 뉴스기사 데이터 실습 (0) | 2021.03.08 |
| 21.03.04. 딥러닝 - (0) | 2021.03.04 |
| 21.03.03. 딥러닝 - 숫자손글씨 인식 마지막, 개고양이 인식 (1) | 2021.03.03 |
| 21.03.02. 딥러닝 - (0) | 2021.03.03 |



