
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- window netstat time wait 제거
- conda base 기본 설정
- 오블완
- conda base 활성화
- time wait port kill
- 려려
- 3000 port kill
- 티스토리챌린지
- conda 기초 설정
- 실행중인 포트 죽이기
- conda 가상환경 설정 오류
- Today
- Total
모도리는 공부중
21.03.08. 딥러닝 - RNN 단어 철자 예측 및 뉴스기사 데이터 실습 본문
21.03.08. 딥러닝 - RNN 단어 철자 예측 및 뉴스기사 데이터 실습
공부하는 모도리 2021. 3. 8. 14:00cnn은 차원이 고차원데이터가 되더라도 학습이 가능하다. 이유는 무얼까? cnn은 특징을 추출해주는 레이어이다. cnn을 붙여서 활용할 수 있는 데이터는 이미지에 국한되지 않는다. 글씨, 소리 등에도 해당이 된다.
cnn과 복합적으로 많이 이용되는 RNN. 오늘은 이것에 대해 배워보도록 한다.

- 순환 신경망에 대해 알 수 있다.
- RNN 의 활용분야를 알 수 있다.
- Keras를 활용해 순환 신경망을 구성할 수 있다.

위의 예시를 보면 알 수 있듯이 실제 문장을 만들기 위해서는 단어 관계 사이를 알고 진행을 해야 한다.
- 문장을 듣고 무엇을 의미하는지 알아야 서비스 제공이 가능하다.
- 문장을 듣고 이해한다는 것은 많은 문장을 이미 학습해 놓았다는 것이다.
- 문장의 의미를 전달하려면 각 단어가 정해진 순서대로 입력되어야 한다.
- 과거에 입력된 데이터와 나중에 입력된 데이터 사이의 관계를 고려해야 하는 문제가 생긴다.
- 이를 해결하기 위해 순환신경망(RNN)이 고안되었다.
일반 신경망과 순환 신경망의 차이
우리가 사진을 분석할 때는 사진데이터를 몽땅 집어넣고 진행했다. 하지만 문장은 단어별로 잘라서 순서를 정해 집어넣어주어야 한다. '오늘'이라는 단어를 넣으면 컴퓨터는 이 단어에 대한 결과를 기억1에 저장을 한다. 그 다음 '주가가'라는 단어가 들어오면 현재 데이터와 과거 데이터를 같이 기억하는 RNN이 두개를 연결지어서 함께 연산시킨 결과값을 기억2에 저장한다. 마지막으로 '몇이야?'가 들어오면 기억2에 저장된 내용을 또 연결지어 연산한다. 이처럼 문장을 한 번에 연산하지 않고 현재 기억값과 과거 기억값을 함께 신경망 안으로 들어오도록 연산하여 출력하는 방식을 취한다.

- 앞에서 나온 입력에 대한 결과가 뒤에서 나오는 입력 값에 영향을 주는 것을 알 수 있다.
- 예를 들어 비슷한 두 문장이 입력되어도 앞에서 나온 입력 값을 구별하여 출력 값에 반영할 수 있다.

- 모든 입력 값에 이 작업을 순서대로 실행하므로 다음 층(layer)으로 넘어가기 전에 같은 층을 맴도는 것처럼 보인다.
- 같은 층안에서 맴도는 성질 때문에 순환 신경망이라고 부른다.

일반 신경망은 기억이 한 가지라면 RNN 신경망은 시간이라는 개념을 이용하여 순차적으로 기억을 이용하는 순환식 방법이라고 할 수 있다. 이렇게 과거의 데이터에 영향을 받는 데이터를 Sequential Data(순차 기반 데이터)라고 부른다. 과거가 미래에 영향을 주는 데이터는 다음과 같다.

여기까지 설명을 들었을 때 CNN과 RNN은 독립적으로만 사용될 것 같지만 실제로는 두 개를 혼합하여 사용하기도 한다. CNN을 이용하여 특성을 추출하고 RNN을 이용하여 순차 데이터를 뽑는 형식으로 말이다.
RNN 수식 살펴보기
RNN은 가중치가 2개이다. 입력데이터에 대한 가중치와 과거에 대한 가중치.



CNN데이터와 구조상으론 크게 다를게 없다. 다만 과거데이터가 현재 데이터와 같이 들어온다는 것뿐.
hello를 SimpleRNN 신경망으로 학습하기

CNN은 4차원 데이터입니다 ^^. (당황하던 해도쌤)
RNN ( Samples, Time steps, Features )
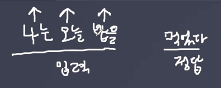
'나는 오늘 밥을 먹었다'에서 '먹었다'를 정답으로 도출하기 위해 time steps는 몇개가 필요할까? 3개가 필요하다. '나는 오늘 밥을'이 이제 하나의 Time steps가 되었다면 이것을 몇개의 Features로 넣을 것인지, 예를 들어 5개로 한다면 '나는'을 '5개'의 숫자로, '오늘'과 '집에'도 마찬가지로 '5개'의 숫자로 표현해서 입력이 들어가게 된다.
Q. '나는', '오늘', '집에'는 글자 수가 2개로 동일한데 만약에 낱말의 글자 수가 서로 달라도 FEATURE를 동일하게 적용하나요?
A. 맞다. 앞서 실습했던 CNN도 여러 개의 사이즈로 구성된 데이터들을 하나의 사이즈로 통일시켜서 학습을 시키고 테스트를 진행했다. 글자도 마찬가지이다. 낱말의 글자수가 몇개이든 상관없이 모두 같은 Features를 가지도록 설정해야 한다. 구조는 계속 그런식으로 들어간다는 것을 인지하고 수업에 들어가도록 하자.

RNN은 SimpleRNN을 사용한다. 그리고 samples 수를 제외하고 time steps와 features만 사용한다.
실습 시작-
데이터셋 구축하기
- char단위 RNN (글자 하나하나씩)
- hello, apple, lobby, daddy, bobby
- 위의 5개 샘플을 학습
- hell이 문제, 0가 답. appl이 문제, e가 답.
- time steps가 4개 들어가면 5번째를 답으로 도출하도록 실습
- 샘플 철자를 하나씩 보면 중복되는 문자들이 있다. (l, p, b, d) → 중복은 제거한다.
- 처음 등장한 순서대로 핫인코딩 번호를 매긴다.


핫인코딩을 직접 해봅시다.


수기 핫인코딩 코드 ↓
# 데이터 3차원
# 원핫인코딩
X_train = np.array(
[
[[1,0,0,0,0,0,0,0,0],[0,1,0,0,0,0,0,0,0],[0,0,1,0,0,0,0,0,0],[0,0,1,0,0,0,0,0,0]],
[[0,0,0,0,1,0,0,0,0],[0,0,0,0,0,1,0,0,0],[0,0,0,0,0,1,0,0,0],[0,0,0,1,0,0,0,0,0]],
[[0,0,0,1,0,0,0,0,0],[0,0,0,1,0,0,0,0,0],[0,0,0,0,0,0,1,0,0],[0,0,0,0,0,0,1,0,0]],
[[0,0,0,0,0,0,0,0,1],[0,0,0,0,1,0,0,0,0],[0,0,0,0,0,0,0,0,1],[0,0,0,0,0,0,0,0,1]],
[[0,0,0,0,0,0,1,0,0],[0,0,0,1,0,0,0,0,0],[0,0,0,0,0,0,1,0,0],[0,0,0,0,0,0,1,0,0]]
]
)y_train = np.array(
[
[0,0,0,1,0,0,0,0,0],
[0,1,0,0,0,0,0,0,0],
[0,0,0,0,0,0,0,1,0],
[0,0,0,0,0,0,0,1,0],
[0,0,0,0,0,0,0,1,0]
]
)핫인코딩한 train데이터의 크기를 확인해본다.
# samples, time steps, features
X_train.shape, y_train.shapeout : ((5, 4, 9), (5, 9))
모델링
from tensorflow.keras import Sequential
from tensorflow.keras.layers import SimpleRNN, Dense # Dense : 뉴런의 묶음들, SimpleRNN : 순환하는 구조의 RNNmodel = Sequential()
# 입력층
model.add(SimpleRNN(8, input_shape=(4, 9))) # 4번 순환하는데 각 시간대마다 9개의 숫자가 입력되는 구조
# 출력층
model.add(Dense(9, activation="softmax"))
# 컴파일
model.compile(loss='categorical_crossentropy', optimizer='Adam', metrics=['accuracy'])
# 학습
model.fit(X_train, y_train, epochs=2000)out : 2000번을 학습시킨 관계로 데이터가 너무 많아서 앞과 뒤를 20개씩 잘라서 첨부.
| Train on 5 samples Epoch 1/2000 5/5 [==============================] - 1s 279ms/sample - loss: 2.2090 - accuracy: 0.2000 Epoch 2/2000 5/5 [==============================] - 0s 2ms/sample - loss: 2.1950 - accuracy: 0.2000 Epoch 3/2000 5/5 [==============================] - 0s 997us/sample - loss: 2.1811 - accuracy: 0.2000 Epoch 4/2000 5/5 [==============================] - 0s 804us/sample - loss: 2.1672 - accuracy: 0.2000 Epoch 5/2000 5/5 [==============================] - 0s 793us/sample - loss: 2.1533 - accuracy: 0.2000 Epoch 6/2000 5/5 [==============================] - 0s 997us/sample - loss: 2.1394 - accuracy: 0.2000 Epoch 7/2000 5/5 [==============================] - 0s 997us/sample - loss: 2.1255 - accuracy: 0.2000 Epoch 8/2000 5/5 [==============================] - 0s 997us/sample - loss: 2.1117 - accuracy: 0.2000 Epoch 9/2000 5/5 [==============================] - 0s 798us/sample - loss: 2.0978 - accuracy: 0.2000 Epoch 10/2000 5/5 [==============================] - 0s 798us/sample - loss: 2.0840 - accuracy: 0.2000 Epoch 11/2000 5/5 [==============================] - 0s 798us/sample - loss: 2.0702 - accuracy: 0.2000 Epoch 12/2000 5/5 [==============================] - 0s 793us/sample - loss: 2.0564 - accuracy: 0.2000 Epoch 13/2000 5/5 [==============================] - 0s 993us/sample - loss: 2.0426 - accuracy: 0.2000 Epoch 14/2000 5/5 [==============================] - 0s 991us/sample - loss: 2.0288 - accuracy: 0.2000 Epoch 15/2000 5/5 [==============================] - 0s 1ms/sample - loss: 2.0151 - accuracy: 0.2000 Epoch 16/2000 5/5 [==============================] - 0s 793us/sample - loss: 2.0013 - accuracy: 0.2000 Epoch 17/2000 5/5 [==============================] - 0s 997us/sample - loss: 1.9875 - accuracy: 0.2000 Epoch 18/2000 5/5 [==============================] - 0s 793us/sample - loss: 1.9738 - accuracy: 0.2000 Epoch 19/2000 5/5 [==============================] - 0s 998us/sample - loss: 1.9601 - accuracy: 0.2000 Epoch 20/2000 5/5 [==============================] - 0s 997us/sample - loss: 1.9463 - accuracy: 0.2000 ....... Epoch 1980/2000 5/5 [==============================] - 0s 997us/sample - loss: 0.0055 - accuracy: 1.0000 Epoch 1981/2000 5/5 [==============================] - 0s 793us/sample - loss: 0.0055 - accuracy: 1.0000 Epoch 1982/2000 5/5 [==============================] - 0s 801us/sample - loss: 0.0055 - accuracy: 1.0000 Epoch 1983/2000 5/5 [==============================] - 0s 997us/sample - loss: 0.0055 - accuracy: 1.0000 Epoch 1984/2000 5/5 [==============================] - 0s 793us/sample - loss: 0.0055 - accuracy: 1.0000 Epoch 1985/2000 5/5 [==============================] - 0s 997us/sample - loss: 0.0055 - accuracy: 1.0000 Epoch 1986/2000 5/5 [==============================] - 0s 997us/sample - loss: 0.0055 - accuracy: 1.0000 Epoch 1987/2000 5/5 [==============================] - 0s 1ms/sample - loss: 0.0055 - accuracy: 1.0000 Epoch 1988/2000 5/5 [==============================] - 0s 791us/sample - loss: 0.0055 - accuracy: 1.0000 Epoch 1989/2000 5/5 [==============================] - 0s 598us/sample - loss: 0.0055 - accuracy: 1.0000 Epoch 1990/2000 5/5 [==============================] - 0s 996us/sample - loss: 0.0055 - accuracy: 1.0000 Epoch 1991/2000 5/5 [==============================] - 0s 798us/sample - loss: 0.0055 - accuracy: 1.0000 Epoch 1992/2000 5/5 [==============================] - 0s 798us/sample - loss: 0.0055 - accuracy: 1.0000 Epoch 1993/2000 5/5 [==============================] - 0s 793us/sample - loss: 0.0055 - accuracy: 1.0000 Epoch 1994/2000 5/5 [==============================] - 0s 797us/sample - loss: 0.0055 - accuracy: 1.0000 Epoch 1995/2000 5/5 [==============================] - 0s 803us/sample - loss: 0.0055 - accuracy: 1.0000 Epoch 1996/2000 5/5 [==============================] - 0s 793us/sample - loss: 0.0054 - accuracy: 1.0000 Epoch 1997/2000 5/5 [==============================] - 0s 803us/sample - loss: 0.0054 - accuracy: 1.0000 Epoch 1998/2000 5/5 [==============================] - 0s 793us/sample - loss: 0.0054 - accuracy: 1.0000 Epoch 1999/2000 5/5 [==============================] - 0s 1ms/sample - loss: 0.0054 - accuracy: 1.0000 Epoch 2000/2000 5/5 [==============================] - 0s 992us/sample - loss: 0.0054 - accuracy: 1.0000 |
parameter에 대해 학습해봅시다.
model.summary()| Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= simple_rnn (SimpleRNN) (None, 8) 144 _________________________________________________________________ dense (Dense) (None, 9) 81 ================================================================= Total params: 225 Trainable params: 225 Non-trainable params: 0 _________________________________________________________________ |
출력층의 학습은 다음 그림과 같이 일어난다.
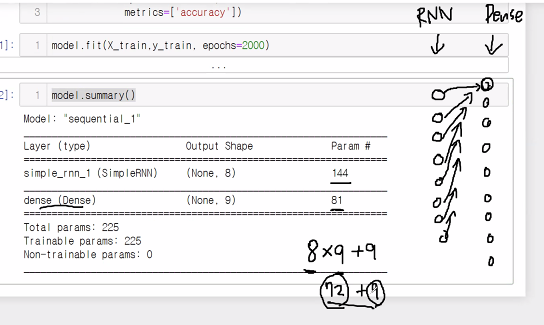
파라미터 144개에 대한 설명
입력에 대해서 9개 등장, 뉴런은 8개를 가지고 있으므로 9 * 8.
뉴런에 대한 절편은 현재 8개이므로 8개를 학습시키는 9 * 8 + 8.
64개는 과거 데이터에 대한 가중치. 64개는 8 * 8이다. 왜?

RNN이 순환형식이기 때문에 현재 데이터에 대한 가중치와 과거 데이터에 대한 가중치가 있으므로..
결론 : RNN은 과거 데이터를 학습한다. 끄읕~... (수학적인 부분은 중요치 않으니 적당히 넘어갑시다!)
RNN은 시간적인 부분이 들어오다보니 활용할 수 있는 면이 다양하다. 층을 어떻게 쌓느냐에 따라 결과값도 달라진다.
RNN 활용구조
1. 다수 입력 단일 출력 (문장 예시)
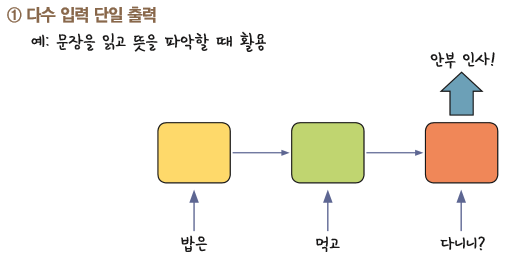
문장이 들어오면 문장의 종류를 맞히는 형식으로 설계된 상태이다.

2. 단일 입력 다수 출력 (사진 예시)
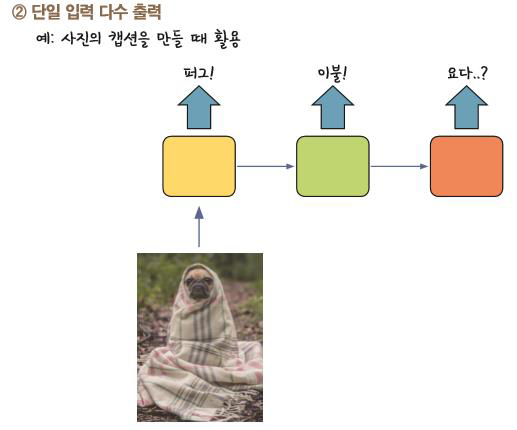
코드로 작성한다면 RepeatVector를 이용해서 만들어줄 수 있다.

3. Video에서 Frame단위 Classfication
기존은 영상의 최종 frame 하나만 예측 결과를 뽑아주는 형태였다면 이것은 매 frame마다 예측하는 형태로 사용된다.
예시 영상 ↓
기본적으로 RNN에 아무 설정을 안하면 다수 입력 단일 출력으로 설정된다. 하지만 다음 코드식처럼 설정을 해주면 매 순간마다 예측결과를 출력하는 방식으로 가능하다.

4. 다수 입력 다수 출력
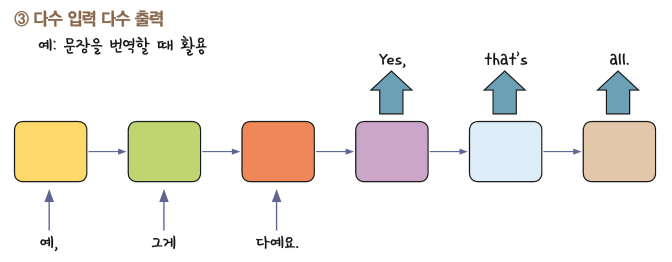
앞에 RNN이 하나 있고, 뒤에 RNN이 또 있는 형태.
이처럼 어떤 글자가 들어오면 RNN이 자기 규칙에 맞추어서 인코딩하고 디코더에 집어넣으면 다시 해석해주는 구조로 되어있다. 같은 다수입력의 다수출력도 구조가 이렇게 다르다.
방금까지 단어 철자를 하나씩 하는 실습을 했다면 keras에 내장된 데이터셋을 활용하여 문장들을 학습시키는 실습을 해봅시다.
어떤 뉴스가 입력되면 이 뉴스의 주제는 무엇인지 분류해주는 다중분류
from tensorflow.keras.datasets import reuters
import numpy as np
import matplotlib.pyplot as plt# 데이터가 넘어올때부터 train과 test형태로 넘어온다.
(X_train, y_train), (X_test, y_test) = reuters.load_data()
# keras에서 데이터가 넘어올 때 이미 이중튜플(데이터 수정이 되지 않도록) 형태로 만들어져 있다.
# 파이썬에서는 콤마를 찍으면 자동으로 튜플형태로 인식해서 감싸준다.루이터뉴스를 먼저 불러와서 train data와 test data로 나누어 변수로 담아준다.
print(X_train.shape)
print(y_train.shape)
print(X_test.shape)
print(y_test.shape)out :
(8982,)
(8982,)
(2246,)
(2246,)
# 첫 번째 뉴스기사 확인
X_train[0]
# 전처리가 끝난 숫자 형태로 데이터가 제공된 상태이며 각 숫자가 하나의 단어이다.
# label 인코딩된 결과값이며 같은 숫자가 등장한다면 같은 단어로 인식된 상태임을 기억하자.out :
| [1, 27595, 28842, 8, 43, 10, 447, 5, 25, 207, 270, 5, 3095, 111, 16, 369, 186, 90, 67, 7, 89, 5, 19, 102, 6, 19, 124, 15, 90, 67, 84, 22, 482, 26, 7, 48, 4, 49, 8, 864, 39, 209, 154, 6, 151, 6, 83, 11, 15, 22, 155, 11, 15, 7, 48, 9, 4579, 1005, 504, 6, 258, 6, 272, 11, 15, 22, 134, 44, 11, 15, 16, 8, 197, 1245, 90, 67, 52, 29, 209, 30, 32, 132, 6, 109, 15, 17, 12] |
print(len(X_train[0]))
# (정확히 따지면 87개는 아니지만..) 첫 번째 뉴스는 87개의 데이터로 구성된 상태
print(len(X_train[1]))
# 두 번째 뉴스는 56개의 데이터로 구성된 상태out으로 87과 56이 나온다.
현재 데이터에 있는 라벨은 아무런 규칙없이 매겨진 것이 아니다.
- 각 단어들의 등장빈도를 기반으로 라벨 매핑된 상태
- 숫자가 작을수록 등장빈도가 낮으며 클수록 등장빈도가 높다.
# 단어 순위표(?) - 빈도 기반 라벨링된 word ranking
reuters.get_word_index()# 정답데이터 개수 확인
np.unique(y_train) # 뉴스 주제 개수 알아보기 (46가지 확인)
# RNN을 활용하면 뉴스에 등장하는 단어의 순서도 중요해진다.뉴스 기사의 단어가 너무 길다? 잘라낸다. 짧다? 패딩작업을 통해 의미없는 빈 숫자를 채워넣는다. 그런식으로 전체 뉴스기사를 똑같은 크기로 맞춰준다. 이런 작업을 하려면 내가 가져오려는 데이터셋의 크기가 어느정도가 적합할지를 먼저 알아봐야할 것이다.
그럼 내가 가져오고자 하는 뉴스 기사 중 단어가 제일 긴 것을 사용하면 될까? 그렇지 않다. RNN은 순환이 많으면 많아질수록 기울기 소실 문제가 발생할 수 있다. 다른 뉴스 기사는 길이가 그렇게 길지 않은데 그 기사 하나만 유독 길이가 길게 나온 것일 수 있기 때문에 중앙값을 잘 찾아서 길이를 맞춰주는 것이 중요하다.
몇 번의 순환을 가질지 시퀀스 길이를 맞춰주도록 하자.
# 뉴스 기사들의 길이 계산
train_len = [ len(doc) for doc in X_train ]
print("최대값 : ", max(train_len))
print("최소값 : ", min(train_len))
print("평균값 : ", np.mean(train_len))
print("중앙값 : ", np.median(train_len))out :
최대값 : 2376
최소값 : 13
평균값 : 145.5398574927633
중앙값 : 95.0
plt.hist(train_len, bins=20)
plt.show()out :
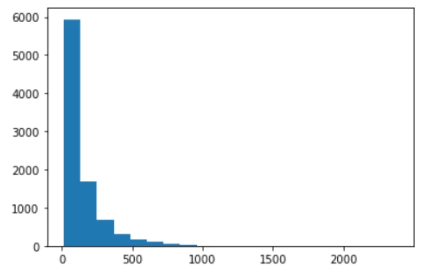
전체 분포를 고려해 110개 정도 시퀀스 길이(time step)로 만든다.
- 개수는 자신이 임의로 정하는 것이므로 부담 가지지 말고 직접 설계해보아도 좋다.
그럼 110개 이상의 뉴스들은 다 버리는건가요? 라는 질문이 들어올 수 있다. 딥러닝은 많은 양의 데이터를 학습시켜서 결과를 얻어내는 방식인데 분포가 많지 않은 110개 이상의 데이터를 학습시켜봤자 유의미한 데이터를 얻기 어려울 수 있다. 그러므로 가장 분포가 많은 데이터를 학습시키는 것이 적합하다.
from tensorflow.keras.preprocessing import sequence # 시퀀스 길이 맞추는 용도
from tensorflow.keras.utils import to_categorical # 정답 → 확률 정보 변경
X_train_pad = sequence.pad_sequences(X_train, maxlen=110)
X_test_pad = sequence.pad_sequences(X_test, maxlen=110)
X_train_pad[0]
# sample은 8982개, 길이(time steps)는 110개
X_train_pad.shapeout : (8982, 110)
features는 1개이다. 한 번 들어가는 단어가 1로 표현된다.
X_train_pad_reshape = X_train_pad.reshape(X_train_pad.shape[0], # 8982
X_train_pad.shape[1], # 110
1)
X_test_pad_reshape = X_test_pad.reshape(X_test_pad.shape[0], # 2246
X_test_pad.shape[1], # 110
1)print(X_train_pad_reshape.shape)
print(X_test_pad_reshape.shape)out :
(8982, 110, 1)
(2246, 110, 1)
정답데이터 확률정보로 변경
- 1번 주제? : 1번 주제일 확률 100%, 2번일 확률 0%, 3번일 확률 0%로 원핫인코딩
y_train_one_hot = to_categorical(y_train)
y_test_one_hot = to_categorical(y_test)모델링
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense, SimpleRNN
model = Sequential()
model.add(SimpleRNN(32, input_shape=(110, 1)))
model.add(Dense(16, activation='relu'))
model.add(Dense(46, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='Adam', metrics=['accuracy'])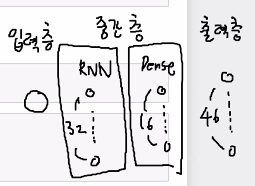
history = model.fit(X_train_pad_reshape, y_train_one_hot, validation_split=0.2, epochs=50)| Train on 7185 samples, validate on 1797 samples Epoch 1/50 7185/7185 [==============================] - 8s 1ms/sample - loss: 2.6609 - accuracy: 0.3485 - val_loss: 2.4282 - val_accuracy: 0.3450 Epoch 2/50 7185/7185 [==============================] - 7s 1ms/sample - loss: 2.4154 - accuracy: 0.3534 - val_loss: 2.4069 - val_accuracy: 0.3450 Epoch 3/50 7185/7185 [==============================] - 7s 1ms/sample - loss: 2.4074 - accuracy: 0.3534 - val_loss: 2.4056 - val_accuracy: 0.3450 Epoch 4/50 7185/7185 [==============================] - 7s 988us/sample - loss: 2.4062 - accuracy: 0.3534 - val_loss: 2.4085 - val_accuracy: 0.3450 Epoch 5/50 7185/7185 [==============================] - 7s 1ms/sample - loss: 2.4059 - accuracy: 0.3534 - val_loss: 2.4138 - val_accuracy: 0.3450 Epoch 6/50 7185/7185 [==============================] - 7s 985us/sample - loss: 2.4057 - accuracy: 0.3534 - val_loss: 2.4081 - val_accuracy: 0.3450 Epoch 7/50 7185/7185 [==============================] - 7s 1ms/sample - loss: 2.4057 - accuracy: 0.3534 - val_loss: 2.4061 - val_accuracy: 0.3450 Epoch 8/50 7185/7185 [==============================] - 7s 1ms/sample - loss: 2.4030 - accuracy: 0.3534 - val_loss: 2.3960 - val_accuracy: 0.3450 Epoch 9/50 7185/7185 [==============================] - 7s 1ms/sample - loss: 2.3903 - accuracy: 0.3534 - val_loss: 2.3853 - val_accuracy: 0.3450 Epoch 10/50 7185/7185 [==============================] - 7s 1ms/sample - loss: 2.3802 - accuracy: 0.3552 - val_loss: 2.3777 - val_accuracy: 0.3450 Epoch 11/50 7185/7185 [==============================] - 7s 1ms/sample - loss: 2.3678 - accuracy: 0.3562 - val_loss: 2.3609 - val_accuracy: 0.3556 Epoch 12/50 7185/7185 [==============================] - 7s 1ms/sample - loss: 2.3612 - accuracy: 0.3599 - val_loss: 2.3606 - val_accuracy: 0.3517 Epoch 13/50 7185/7185 [==============================] - 7s 1ms/sample - loss: 2.3544 - accuracy: 0.3634 - val_loss: 2.3527 - val_accuracy: 0.3567 Epoch 14/50 7185/7185 [==============================] - 7s 1ms/sample - loss: 2.3445 - accuracy: 0.3645 - val_loss: 2.3431 - val_accuracy: 0.3589 Epoch 15/50 7185/7185 [==============================] - 7s 977us/sample - loss: 2.3352 - accuracy: 0.3621 - val_loss: 2.3338 - val_accuracy: 0.3589 Epoch 16/50 7185/7185 [==============================] - 7s 1ms/sample - loss: 2.3303 - accuracy: 0.3587 - val_loss: 2.3423 - val_accuracy: 0.3578 Epoch 17/50 7185/7185 [==============================] - 7s 1ms/sample - loss: 2.3247 - accuracy: 0.3687 - val_loss: 2.3496 - val_accuracy: 0.3283 Epoch 18/50 7185/7185 [==============================] - 7s 1ms/sample - loss: 2.3270 - accuracy: 0.3642 - val_loss: 2.3409 - val_accuracy: 0.3456 Epoch 19/50 7185/7185 [==============================] - 7s 1ms/sample - loss: 2.3237 - accuracy: 0.3665 - val_loss: 2.3314 - val_accuracy: 0.3656 Epoch 20/50 7185/7185 [==============================] - 7s 1ms/sample - loss: 2.3212 - accuracy: 0.3663 - val_loss: 2.3306 - val_accuracy: 0.3589 Epoch 21/50 7185/7185 [==============================] - 7s 996us/sample - loss: 2.3185 - accuracy: 0.3649 - val_loss: 2.3303 - val_accuracy: 0.3567 Epoch 22/50 7185/7185 [==============================] - 7s 1ms/sample - loss: 2.3105 - accuracy: 0.3630 - val_loss: 2.3282 - val_accuracy: 0.3578 Epoch 23/50 7185/7185 [==============================] - 7s 1ms/sample - loss: 2.3078 - accuracy: 0.3653 - val_loss: 2.3220 - val_accuracy: 0.3472 Epoch 24/50 7185/7185 [==============================] - 7s 1ms/sample - loss: 2.3045 - accuracy: 0.3690 - val_loss: 2.3224 - val_accuracy: 0.3600 Epoch 25/50 7185/7185 [==============================] - 7s 1ms/sample - loss: 2.3011 - accuracy: 0.3683 - val_loss: 2.3131 - val_accuracy: 0.3617 Epoch 26/50 7185/7185 [==============================] - 7s 999us/sample - loss: 2.2972 - accuracy: 0.3652 - val_loss: 2.3138 - val_accuracy: 0.3506 Epoch 27/50 7185/7185 [==============================] - 7s 1ms/sample - loss: 2.2948 - accuracy: 0.3673 - val_loss: 2.3112 - val_accuracy: 0.3623 Epoch 28/50 7185/7185 [==============================] - 7s 1ms/sample - loss: 2.2906 - accuracy: 0.3683 - val_loss: 2.3043 - val_accuracy: 0.3528 Epoch 29/50 7185/7185 [==============================] - 7s 996us/sample - loss: 2.2882 - accuracy: 0.3733 - val_loss: 2.3480 - val_accuracy: 0.3434 Epoch 30/50 7185/7185 [==============================] - 7s 1ms/sample - loss: 2.2934 - accuracy: 0.3699 - val_loss: 2.3044 - val_accuracy: 0.3623 Epoch 31/50 7185/7185 [==============================] - 7s 1ms/sample - loss: 2.2835 - accuracy: 0.3670 - val_loss: 2.2988 - val_accuracy: 0.3634 Epoch 32/50 7185/7185 [==============================] - 7s 1ms/sample - loss: 2.2806 - accuracy: 0.3737 - val_loss: 2.2963 - val_accuracy: 0.3623 Epoch 33/50 7185/7185 [==============================] - 7s 1ms/sample - loss: 2.2764 - accuracy: 0.3748 - val_loss: 2.2955 - val_accuracy: 0.3612 Epoch 34/50 7185/7185 [==============================] - 7s 1ms/sample - loss: 2.2737 - accuracy: 0.3722 - val_loss: 2.2947 - val_accuracy: 0.3600 Epoch 35/50 7185/7185 [==============================] - 7s 998us/sample - loss: 2.2730 - accuracy: 0.3722 - val_loss: 2.2971 - val_accuracy: 0.3589 Epoch 36/50 7185/7185 [==============================] - 7s 1ms/sample - loss: 2.2697 - accuracy: 0.3701 - val_loss: 2.2971 - val_accuracy: 0.3639 Epoch 37/50 7185/7185 [==============================] - 7s 1ms/sample - loss: 2.2687 - accuracy: 0.3715 - val_loss: 2.2969 - val_accuracy: 0.3617 Epoch 38/50 7185/7185 [==============================] - 7s 1ms/sample - loss: 2.2669 - accuracy: 0.3762 - val_loss: 2.2937 - val_accuracy: 0.3511 Epoch 39/50 7185/7185 [==============================] - 7s 1ms/sample - loss: 2.2638 - accuracy: 0.3692 - val_loss: 2.2899 - val_accuracy: 0.3606 Epoch 40/50 7185/7185 [==============================] - 7s 1ms/sample - loss: 2.2630 - accuracy: 0.3698 - val_loss: 2.3047 - val_accuracy: 0.3662 Epoch 41/50 7185/7185 [==============================] - 7s 987us/sample - loss: 2.2628 - accuracy: 0.3719 - val_loss: 2.2881 - val_accuracy: 0.3606 Epoch 42/50 7185/7185 [==============================] - 7s 1ms/sample - loss: 2.2607 - accuracy: 0.3697 - val_loss: 2.2847 - val_accuracy: 0.3623 Epoch 43/50 7185/7185 [==============================] - 7s 1ms/sample - loss: 2.2585 - accuracy: 0.3745 - val_loss: 2.2861 - val_accuracy: 0.3612 Epoch 44/50 7185/7185 [==============================] - 7s 1ms/sample - loss: 2.2563 - accuracy: 0.3687 - val_loss: 2.3034 - val_accuracy: 0.3550 Epoch 45/50 7185/7185 [==============================] - 7s 1ms/sample - loss: 2.2582 - accuracy: 0.3733 - val_loss: 2.2851 - val_accuracy: 0.3617 Epoch 46/50 7185/7185 [==============================] - 7s 1ms/sample - loss: 2.2545 - accuracy: 0.3723 - val_loss: 2.2906 - val_accuracy: 0.3550 Epoch 47/50 7185/7185 [==============================] - 7s 1ms/sample - loss: 2.2552 - accuracy: 0.3738 - val_loss: 2.2830 - val_accuracy: 0.3662 Epoch 48/50 7185/7185 [==============================] - 7s 1ms/sample - loss: 2.2501 - accuracy: 0.3777 - val_loss: 2.2907 - val_accuracy: 0.3617 Epoch 49/50 7185/7185 [==============================] - 7s 1ms/sample - loss: 2.2510 - accuracy: 0.3720 - val_loss: 2.2860 - val_accuracy: 0.3606 - loss: 2.2 Epoch 50/50 7185/7185 [==============================] - 7s 1ms/sample - loss: 2.2488 - accuracy: 0.3768 - val_loss: 2.2804 - val_accuracy: 0.3689 |
plt.figure(figsize=(10, 5))
plt.plot(history.history['val_loss'], label='val_loss')
plt.plot(history.history['loss'], label='loss')
plt.legend()
plt.show()
plt.figure(figsize=(10, 5))
plt.plot(history.history['val_accuracy'], label='val_acc')
plt.plot(history.history['accuracy'], label='acc')
plt.legend()
plt.show()
'K-디지털 빅데이터 분석서비스 개발자과정 20.11.02~21.04.12 > PYTHON(웹크롤링, 머신·딥러닝)' 카테고리의 다른 글
| 21.03.11. 딥러닝 - 시계열 RNN (4) | 2021.03.11 |
|---|---|
| 21.03.09. 딥러닝 - RNN, LSTM, 단어 임베딩 (0) | 2021.03.09 |
| 21.03.05. 딥러닝 - 동물 이미지 인식, 패션 이미지 분류 (0) | 2021.03.05 |
| 21.03.04. 딥러닝 - (0) | 2021.03.04 |
| 21.03.03. 딥러닝 - 숫자손글씨 인식 마지막, 개고양이 인식 (1) | 2021.03.03 |



