
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- conda 기초 설정
- 실행중인 포트 죽이기
- 티스토리챌린지
- conda base 기본 설정
- window netstat time wait 제거
- 오블완
- conda base 활성화
- conda 가상환경 설정 오류
- 려려
- time wait port kill
- 3000 port kill
Archives
- Today
- Total
모도리는 공부중
21.03.04. 딥러닝 - 본문
K-디지털 빅데이터 분석서비스 개발자과정 20.11.02~21.04.12/PYTHON(웹크롤링, 머신·딥러닝)
21.03.04. 딥러닝 -
공부하는 모도리 2021. 3. 4. 18:04728x90
반응형
전이학습(Transfer Learning)
- 전이학습이란 다른 데이터 셋을 사용하여 이미 학습한 모델을 유사한 다른 데이터를 인식하는데 사용하는 기법이다.
- 이 방법은 특히 새로 훈련시킬 데이터가 충분히 확보되지 못한 경우에 학습 효율을 높여준다.
- 사전학습모델을 이용하는 방법은 특성 추출(feature extraction)방식과 미세조정(fine tuning) 방식이 있다.

- VCG16의 구조 : 컨볼루션층 13개, MaxPooling 5개, Fully Connected Layer 4개로 구성
- 최종적으로 특성 맵의 크기는 (4, 4, 512)



컨볼루션 베이스 - 특성 추출 방식 (Feature Extractor) ← 우린 이 방식을 주로 사용한다.
전결합층 분류기 (Classfier)
전이학습 - 특성추출 방식

- 컨볼류션 베이스 부분만 재사용하는 이유는 이 부분은 상당히 일반적인 학습정보를 포함하고 있기 때문이다.
- 컨볼류션 계층에서도 재사용할 수 있는 정보의 수준은 몇 번째 계층인지에 따라 다르다. 모델의 앞 단의 계층일수록 에지, 색상, 텍스처 등 일반적인 정보를 담는다.
- 반면에 뒷 부분의 깊은 계층일수록 추상적인 정보를 담는다(예를 들어 고양이 귀, 강아지 귀 등).
- 새롭게 분류할 클래스의 종류가 사전 학습에 사용된 데이터와 특성이 매우 다르면, 컨볼류션 베이스 전체를 재사용해서는 안되고 앞단의 일부 계층만을 재사용해야 한다.
전이학습 - 미세조정 방식
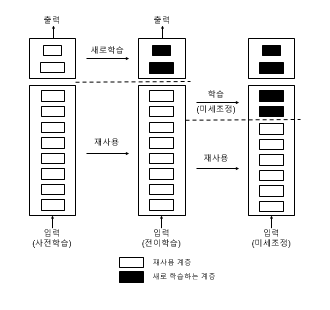
- 미세 조정 : 특성 추출에 사용했던 동결 모델의 상위 층 몇 개를 동결에서 해제 하고 모델에 새로 추가한 층 여기에서는 Fully Connected Layer) 과 함께 훈련하는 것
- 주어진 문제에 조금 더 밀접하게 재사용 모델의 표현을 일부 조정 → 미세 조정

오차역전파를 마지막층 바로 전까지만 한다. 동결은 오차역전파가 되지 않도록 하는 작업.
파이썬으로 코드를 적으면서 직접 실습해봅시다.
전이학습 (Transfer learning)
- 잘 설계되고 잘 학습된 모델을 가져다가 사용하는 것
- 특성추출 : 기존의 Conv 모델을 그대로 가져다 쓰는 것
- 기존의 Conv 모델을 함수형태로 사용하는 것
- 기존의 Conv 모델을 우리가 설계모델 대신에 삽입해서 사용하는 것
- 미세조정 : 기존의 Conv 모델을 그대로 가져다 일부를 변경해서 쓰는 것
VGG16 모델을 전이학습
from tensorflow.keras.applications import VGG16
# weights : 초기화할 가중치
# include_top = False : 분류기(Dense)를 빼고 Conv레이어만 사용하겠다.
# - True로 두면 Dense층이 추가된다
# input_shape : VGG16에 넣어줄 입력 크기
conv_base = VGG16(weights="imagenet", include_top = False, input_shape=(150, 150, 3))
conv_base.summary()out :
| Model: "vgg16" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_1 (InputLayer) [(None, 150, 150, 3)] 0 _________________________________________________________________ block1_conv1 (Conv2D) (None, 150, 150, 64) 1792 _________________________________________________________________ block1_conv2 (Conv2D) (None, 150, 150, 64) 36928 _________________________________________________________________ block1_pool (MaxPooling2D) (None, 75, 75, 64) 0 _________________________________________________________________ block2_conv1 (Conv2D) (None, 75, 75, 128) 73856 _________________________________________________________________ block2_conv2 (Conv2D) (None, 75, 75, 128) 147584 _________________________________________________________________ block2_pool (MaxPooling2D) (None, 37, 37, 128) 0 _________________________________________________________________ block3_conv1 (Conv2D) (None, 37, 37, 256) 295168 _________________________________________________________________ block3_conv2 (Conv2D) (None, 37, 37, 256) 590080 _________________________________________________________________ block3_conv3 (Conv2D) (None, 37, 37, 256) 590080 _________________________________________________________________ block3_pool (MaxPooling2D) (None, 18, 18, 256) 0 _________________________________________________________________ block4_conv1 (Conv2D) (None, 18, 18, 512) 1180160 _________________________________________________________________ block4_conv2 (Conv2D) (None, 18, 18, 512) 2359808 _________________________________________________________________ block4_conv3 (Conv2D) (None, 18, 18, 512) 2359808 _________________________________________________________________ block4_pool (MaxPooling2D) (None, 9, 9, 512) 0 _________________________________________________________________ block5_conv1 (Conv2D) (None, 9, 9, 512) 2359808 _________________________________________________________________ block5_conv2 (Conv2D) (None, 9, 9, 512) 2359808 _________________________________________________________________ block5_conv3 (Conv2D) (None, 9, 9, 512) 2359808 _________________________________________________________________ block5_pool (MaxPooling2D) (None, 4, 4, 512) 0 ================================================================= Total params: 14,714,688 Trainable params: 14,714,688 Non-trainable params: 0 _________________________________________________________________ |

특성추출 : 함수형태로 사용하는 방법 (증식을 사용하지 않는 방식)
import os
import os.path
import numpy as np
from tensorflow.keras.preprocessing.image import ImageDataGenerator
base_dir = "./data/dogs_vs_cats_small2_2"
train_dir = os.path.join(base_dir, "train")
test_dir = os.path.join(base_dir, "test")
validation_dir = os.path.join(base_dir, "validation")
dataGen = ImageDataGenerator(rescale=1./255)
batch_size = 20
# VGG16에 개고양이 이미지를 입력하고 특성을 추출하여 특성맵을 받는 함수
# 이미지가 있는 폴더명, 폴더에 있는 이미지의 수
def extract_feature(directory, sample_count):
# VGG16으로부터 받은 특성맵을 저장할 리스트
# 4, 4, 512 : VGG16의 출력크기
features = np.zeros(shape=(sample_count, 4, 4, 512))
# 각 이미지의 라벨을 저장하기 위한 리스트
labels = np.zeros(shape=(sample_count))
# VGG16으로 이미지를 전달하기 위한 제너레이터를 설정
generator = dataGen.flow_from_directory(directory,
target_size=(150, 150),
batch_size=batch_size,
class_mode="binary")
# VGG16호출 횟수를 카운트
i = 0
# 폴더에 있는 전체 이미지를 VGG16으로 batch_size 개수만큼씩 전달
# generator로부터 변환된 이미지와 라벨을 20개씩 받는다
for inputs_batch, labels_batch in generator:
# VGG16에 이미지(input_batch)입력으로 주어 특성맵을 받아온다
features_batch = conv_base.predict(inputs_batch)
# features리스트에 20개씩 특성맵을 추가
features[i*batch_size : (i+1)*batch_size] = features_batch
labels[i*batch_size : (i+1)*batch_size] = labels_batch
i = i+1
# 폴더에 있는 이미지수(sample_count)를 (sample_count)만큼 다 처리했다면
if i*batch_size >= sample_count:
braek
return features, labels# trian, validation 폴더에 있는 이미지를 VGG16에 전송해서 특성맵을 추출
train_features, train_labels = extract_feature(train_dir, 2000)
validation_features, validation_labels = extract_feature(validation_dir, 1000)out :
Found 2000 images belonging to 2 classes.
Found 1000 images belonging to 2 classes.
# VGG16에서 넘어온 특성맵이 3차원 데이터이므로 1차원으로 변환
train_features = np.reshape(train_features, (2000, 4*4*512))
validation_features = np.reshape(validation_features, (1000, 4*4*512))
train_features.shape, validation_features.shapeout : ((2000, 8192), (1000, 8192))
설계한 신경망에 VGG16에서 넘어온 특성맵을 적용
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout
model4 = Sequential()
model4.add(Dense(256, input_dim=train_features.shape[1], activation="relu"))
model4.add(Dropout(0.5))
model4.add(Dense(1, activation="sigmoid"))
model4.summary()out :
| Model: "sequential_2" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= dense_2 (Dense) (None, 256) 2097408 _________________________________________________________________ dropout_1 (Dropout) (None, 256) 0 _________________________________________________________________ dense_3 (Dense) (None, 1) 257 ================================================================= Total params: 2,097,665 Trainable params: 2,097,665 Non-trainable params: 0 _________________________________________________________________ |
model4.compile(loss="binary_crossentropy", optimizer="RMSprop", metrics=["acc"])
model4.compile(loss="binary_crossentropy", optimizer="RMSprop", metrics=["acc"])out : (너무 길어서 더보기로 표시)
더보기
| Train on 2000 samples, validate on 1000 samples Epoch 1/30 2000/2000 [==============================] - 1s 385us/sample - loss: 0.5543 - acc: 0.9945 - val_loss: 0.3348 - val_acc: 0.9920 Epoch 2/30 2000/2000 [==============================] - 0s 185us/sample - loss: 0.1856 - acc: 0.9980 - val_loss: 0.0730 - val_acc: 0.9900 Epoch 3/30 2000/2000 [==============================] - 0s 180us/sample - loss: 0.0447 - acc: 0.9985 - val_loss: 0.1065 - val_acc: 0.9910 Epoch 4/30 2000/2000 [==============================] - 0s 179us/sample - loss: 0.0297 - acc: 0.9970 - val_loss: 0.0195 - val_acc: 0.9900 Epoch 5/30 2000/2000 [==============================] - 0s 178us/sample - loss: 0.0133 - acc: 0.9975 - val_loss: 0.1517 - val_acc: 0.9910 Epoch 6/30 2000/2000 [==============================] - 0s 175us/sample - loss: 0.0163 - acc: 0.9985 - val_loss: 0.0856 - val_acc: 0.9910 Epoch 7/30 2000/2000 [==============================] - 0s 175us/sample - loss: 0.0036 - acc: 0.9990 - val_loss: 0.0158 - val_acc: 0.9960 Epoch 8/30 2000/2000 [==============================] - 0s 171us/sample - loss: 0.0037 - acc: 0.9990 - val_loss: 0.0250 - val_acc: 0.9950 Epoch 9/30 2000/2000 [==============================] - 0s 175us/sample - loss: 0.0018 - acc: 0.9995 - val_loss: 0.0928 - val_acc: 0.9910 Epoch 10/30 2000/2000 [==============================] - 0s 171us/sample - loss: 0.0041 - acc: 0.9980 - val_loss: 0.1162 - val_acc: 0.9910 Epoch 11/30 2000/2000 [==============================] - 0s 179us/sample - loss: 0.0093 - acc: 0.9985 - val_loss: 0.0123 - val_acc: 0.9970 Epoch 12/30 2000/2000 [==============================] - 0s 175us/sample - loss: 0.0031 - acc: 0.9985 - val_loss: 0.0166 - val_acc: 0.9950 Epoch 13/30 2000/2000 [==============================] - 0s 174us/sample - loss: 0.0031 - acc: 0.9995 - val_loss: 0.0112 - val_acc: 0.9970 Epoch 14/30 2000/2000 [==============================] - 0s 180us/sample - loss: 1.5355e-04 - acc: 1.0000 - val_loss: 0.0270 - val_acc: 0.9950 Epoch 15/30 2000/2000 [==============================] - 0s 174us/sample - loss: 4.9276e-04 - acc: 0.9995 - val_loss: 0.0288 - val_acc: 0.9950 Epoch 16/30 2000/2000 [==============================] - 0s 180us/sample - loss: 1.9006e-07 - acc: 1.0000 - val_loss: 0.0400 - val_acc: 0.9950 Epoch 17/30 2000/2000 [==============================] - 0s 174us/sample - loss: 0.0036 - acc: 0.9990 - val_loss: 0.0094 - val_acc: 0.9990 Epoch 18/30 2000/2000 [==============================] - 0s 176us/sample - loss: 0.0013 - acc: 0.9995 - val_loss: 0.0118 - val_acc: 0.9970 Epoch 19/30 2000/2000 [==============================] - 0s 187us/sample - loss: 2.0288e-07 - acc: 1.0000 - val_loss: 0.0247 - val_acc: 0.9950 Epoch 20/30 2000/2000 [==============================] - 0s 179us/sample - loss: 1.3642e-04 - acc: 1.0000 - val_loss: 0.0353 - val_acc: 0.9950 Epoch 21/30 2000/2000 [==============================] - 0s 178us/sample - loss: 4.5830e-08 - acc: 1.0000 - val_loss: 0.0157 - val_acc: 0.9970 Epoch 22/30 2000/2000 [==============================] - 0s 180us/sample - loss: 4.7413e-04 - acc: 0.9995 - val_loss: 0.0416 - val_acc: 0.9950 Epoch 23/30 2000/2000 [==============================] - 0s 174us/sample - loss: 1.0843e-08 - acc: 1.0000 - val_loss: 0.0331 - val_acc: 0.9950 Epoch 24/30 2000/2000 [==============================] - 0s 175us/sample - loss: 3.3655e-08 - acc: 1.0000 - val_loss: 0.0136 - val_acc: 0.9970 Epoch 25/30 2000/2000 [==============================] - 0s 185us/sample - loss: 1.9560e-07 - acc: 1.0000 - val_loss: 0.0502 - val_acc: 0.9950 Epoch 26/30 2000/2000 [==============================] - 0s 179us/sample - loss: 5.7936e-09 - acc: 1.0000 - val_loss: 0.0500 - val_acc: 0.9950 Epoch 27/30 2000/2000 [==============================] - 0s 174us/sample - loss: 3.8269e-09 - acc: 1.0000 - val_loss: 0.0508 - val_acc: 0.9950 Epoch 28/30 2000/2000 [==============================] - 0s 175us/sample - loss: 1.5098e-08 - acc: 1.0000 - val_loss: 0.0527 - val_acc: 0.9950 Epoch 29/30 2000/2000 [==============================] - 0s 175us/sample - loss: 4.0409e-06 - acc: 1.0000 - val_loss: 0.0201 - val_acc: 0.9950 Epoch 30/30 2000/2000 [==============================] - 0s 175us/sample - loss: 2.6262e-07 - acc: 1.0000 - val_loss: 0.0250 - val_acc: 0.9950 |
import matplotlib.pyplot as plt
acc = h4.history["acc"]
val_acc = h4.history["val_acc"]
plt.plot(range(1, len()))증식을 이용한 특성 추출
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Flatten
model5 = Sequential()
# VGG16 모델을 추가
model5.add(conv_base)
model5.add(Flatten())
model5.add(Dense(units=256, activation="relu"))
model5.add(Dropout(0.5))
model5.add(Dense(units=1, activation="sigmoid"))
model5.summary()out :
| Model: "sequential_3" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= vgg16 (Model) (None, 4, 4, 512) 14714688 _________________________________________________________________ flatten (Flatten) (None, 8192) 0 _________________________________________________________________ dense_4 (Dense) (None, 256) 2097408 _________________________________________________________________ dropout_2 (Dropout) (None, 256) 0 _________________________________________________________________ dense_5 (Dense) (None, 1) 257 ================================================================= Total params: 16,812,353 Trainable params: 16,812,353 Non-trainable params: 0 _________________________________________________________________ |
- 분류기에서 오차 역전파를 하는 경우 VGG16 모델의 파라미터까지 갱신되는 문제
- 동결 : 전이학습으로 가져온 모델은 학습이 되지 않도록 막아두는 것
# 동결하기 전 학습 가능한 가중치 수
print("동결하기 전의 가중치 수 : ", len(model5.trainable_weights))out : 동결하기 전의 가중치 수 : 30
# 동결 (학습하지 않는다고 설정)
conv_base.trainable = False
# 동결한 후 학습 가능한 가중치 수
print("동결한 후의 가중치 수 : ", len(model5.trainable_weights))out : 동결한 후의 가중치 수 : 4
증식 (데이터 확장)
from tensorflow.keras.preprocessing.image import ImageDataGenerator
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=20,
width_shift_range=0.1,
height_shift_range=0.1,
shear_range=0.1,
zoom_range=0.1,
horizontal_flip=True,
fill_mode='nearest')
# 검증 데이터는 증식되어서는 안됨
validation_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
# 타깃 디렉터리
train_dir,
# 모든 이미지의 크기를 150 × 150로 변경
target_size=(150, 150),
batch_size=20,
# binary_crossentropy 손실을 사용하므로 이진 레이블이 필요
class_mode='binary')
validation_generator = validation_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')out :
Found 2000 images belonging to 2 classes.
Found 1000 images belonging to 2 classes.
model5.compile(loss='binary_crossentropy',
optimizer="RMSprop",
metrics=['acc'])
h5 = model5.fit(
train_generator,
epochs=30,
validation_data=validation_generator)out :
더보기
| WARNING:tensorflow:sample_weight modes were coerced from ... to ['...'] WARNING:tensorflow:sample_weight modes were coerced from ... to ['...'] Train for 100 steps, validate for 50 steps Epoch 1/30 100/100 [==============================] - 15s 154ms/step - loss: 0.8840 - acc: 0.7190 - val_loss: 0.3518 - val_acc: 0.8390 Epoch 2/30 100/100 [==============================] - 13s 127ms/step - loss: 0.4489 - acc: 0.8010 - val_loss: 0.3377 - val_acc: 0.8360 Epoch 3/30 100/100 [==============================] - 13s 125ms/step - loss: 0.3932 - acc: 0.8225 - val_loss: 0.2774 - val_acc: 0.8840 Epoch 4/30 100/100 [==============================] - 12s 125ms/step - loss: 0.3618 - acc: 0.8540 - val_loss: 0.3475 - val_acc: 0.8480 Epoch 5/30 100/100 [==============================] - 12s 125ms/step - loss: 0.3482 - acc: 0.8515 - val_loss: 0.2521 - val_acc: 0.8930 Epoch 6/30 100/100 [==============================] - 12s 124ms/step - loss: 0.3449 - acc: 0.8525 - val_loss: 0.2551 - val_acc: 0.8920 Epoch 7/30 100/100 [==============================] - 12s 125ms/step - loss: 0.3214 - acc: 0.8630 - val_loss: 0.3049 - val_acc: 0.8670 Epoch 8/30 100/100 [==============================] - 12s 124ms/step - loss: 0.3275 - acc: 0.8685 - val_loss: 0.3044 - val_acc: 0.8750 Epoch 9/30 100/100 [==============================] - 12s 124ms/step - loss: 0.3130 - acc: 0.8725 - val_loss: 0.2442 - val_acc: 0.9070 Epoch 10/30 100/100 [==============================] - 12s 124ms/step - loss: 0.2871 - acc: 0.8870 - val_loss: 0.2562 - val_acc: 0.9010 Epoch 11/30 100/100 [==============================] - 12s 124ms/step - loss: 0.3019 - acc: 0.8880 - val_loss: 0.2535 - val_acc: 0.8980 Epoch 12/30 100/100 [==============================] - 12s 124ms/step - loss: 0.2918 - acc: 0.8800 - val_loss: 0.2719 - val_acc: 0.9090 Epoch 13/30 100/100 [==============================] - 12s 123ms/step - loss: 0.3025 - acc: 0.8740 - val_loss: 0.2567 - val_acc: 0.9110 Epoch 14/30 100/100 [==============================] - 12s 124ms/step - loss: 0.2600 - acc: 0.8945 - val_loss: 0.3114 - val_acc: 0.8830 Epoch 15/30 100/100 [==============================] - 12s 124ms/step - loss: 0.2853 - acc: 0.8805 - val_loss: 0.2689 - val_acc: 0.9060 Epoch 16/30 100/100 [==============================] - 12s 124ms/step - loss: 0.2492 - acc: 0.8930 - val_loss: 0.2702 - val_acc: 0.9040 Epoch 17/30 100/100 [==============================] - 12s 125ms/step - loss: 0.2716 - acc: 0.8940 - val_loss: 0.2573 - val_acc: 0.9040 Epoch 18/30 100/100 [==============================] - 12s 124ms/step - loss: 0.2663 - acc: 0.8915 - val_loss: 0.2528 - val_acc: 0.8990 Epoch 19/30 100/100 [==============================] - 12s 124ms/step - loss: 0.2654 - acc: 0.9000 - val_loss: 0.3190 - val_acc: 0.8880 Epoch 20/30 100/100 [==============================] - 12s 124ms/step - loss: 0.2573 - acc: 0.8980 - val_loss: 0.2804 - val_acc: 0.9070 Epoch 21/30 100/100 [==============================] - 12s 124ms/step - loss: 0.2425 - acc: 0.9045 - val_loss: 0.3020 - val_acc: 0.8890 Epoch 22/30 100/100 [==============================] - 12s 124ms/step - loss: 0.2491 - acc: 0.9000 - val_loss: 0.4009 - val_acc: 0.8680 Epoch 23/30 100/100 [==============================] - 12s 124ms/step - loss: 0.2434 - acc: 0.9050 - val_loss: 0.3261 - val_acc: 0.8860 Epoch 24/30 100/100 [==============================] - 12s 124ms/step - loss: 0.2491 - acc: 0.9000 - val_loss: 0.2958 - val_acc: 0.9050 Epoch 25/30 100/100 [==============================] - 12s 124ms/step - loss: 0.2381 - acc: 0.9080 - val_loss: 0.3167 - val_acc: 0.9010 Epoch 26/30 100/100 [==============================] - 12s 124ms/step - loss: 0.2292 - acc: 0.9090 - val_loss: 0.3086 - val_acc: 0.8980 Epoch 27/30 100/100 [==============================] - 12s 125ms/step - loss: 0.2368 - acc: 0.9090 - val_loss: 0.3422 - val_acc: 0.8980 Epoch 28/30 100/100 [==============================] - 12s 124ms/step - loss: 0.2375 - acc: 0.9125 - val_loss: 0.2859 - val_acc: 0.9110 Epoch 29/30 100/100 [==============================] - 12s 124ms/step - loss: 0.2228 - acc: 0.9145 - val_loss: 0.3168 - val_acc: 0.9140 Epoch 30/30 100/100 [==============================] - 12s 124ms/step - loss: 0.2359 - acc: 0.9090 - val_loss: 0.2884 - val_acc: 0.9190 |
import matplotlib.pyplot as plt
acc = h5.history["acc"]
val_acc = h5.history["val_acc"]
plt.plot(range(1, len(acc)+1), acc, label="train_acc")
plt.plot(range(1, len(acc)+1), val_acc, label="test_acc")
plt.legend()out :

미세조정
- 전이학습 모델을 마지막 층 부분까지 학습이 되도록 조정하는 것
동결을 풀어주는 작업
# VGG16의 5번째 레이어만 동결을 풀어줌
conv_base.trainable = True
set_trainable = False
# conv_base 모델의 레이어를 하나씩 가져온다.
for layer in conv_base.layers:
# 레이어 이름이 block5_conv1이면 동결을 풀어줌
if layer.name == "block5_conv1":
set_trainable = True
if set_trainable:
layer.trainable = True
else:
layer.trainable = Falsemodel5.compile(loss='binary_crossentropy',
optimizer="RMSprop",
metrics=['acc'])
h5 = model5.fit(
train_generator,
epochs=30,
validation_data=validation_generator)out :
더보기
| WARNING:tensorflow:sample_weight modes were coerced from ... to ['...'] WARNING:tensorflow:sample_weight modes were coerced from ... to ['...'] Train for 100 steps, validate for 50 steps Epoch 1/30 100/100 [==============================] - 13s 134ms/step - loss: 48.3274 - acc: 0.5250 - val_loss: 0.7331 - val_acc: 0.5000 Epoch 2/30 100/100 [==============================] - 12s 125ms/step - loss: 0.8691 - acc: 0.5170 - val_loss: 0.6909 - val_acc: 0.5570 Epoch 3/30 100/100 [==============================] - 12s 125ms/step - loss: 1.1291 - acc: 0.5635 - val_loss: 0.6486 - val_acc: 0.5380 Epoch 4/30 100/100 [==============================] - 12s 125ms/step - loss: 0.8194 - acc: 0.6900 - val_loss: 0.4461 - val_acc: 0.8050 Epoch 5/30 100/100 [==============================] - 12s 124ms/step - loss: 1.2450 - acc: 0.7765 - val_loss: 0.2602 - val_acc: 0.9070 Epoch 6/30 100/100 [==============================] - 12s 124ms/step - loss: 1.0449 - acc: 0.8200 - val_loss: 0.2246 - val_acc: 0.9140 Epoch 7/30 100/100 [==============================] - 12s 124ms/step - loss: 0.4554 - acc: 0.8615 - val_loss: 0.2574 - val_acc: 0.8890 Epoch 8/30 100/100 [==============================] - 12s 124ms/step - loss: 0.4290 - acc: 0.8600 - val_loss: 0.2413 - val_acc: 0.9270 Epoch 9/30 100/100 [==============================] - 12s 124ms/step - loss: 0.4694 - acc: 0.8835 - val_loss: 1.9628 - val_acc: 0.6930 Epoch 10/30 100/100 [==============================] - 12s 123ms/step - loss: 0.3213 - acc: 0.8890 - val_loss: 0.2775 - val_acc: 0.8980 Epoch 11/30 100/100 [==============================] - 13s 125ms/step - loss: 0.3149 - acc: 0.8960 - val_loss: 0.2011 - val_acc: 0.9190 Epoch 12/30 100/100 [==============================] - 12s 125ms/step - loss: 0.3184 - acc: 0.9065 - val_loss: 0.2399 - val_acc: 0.9220 Epoch 13/30 100/100 [==============================] - 12s 124ms/step - loss: 0.3109 - acc: 0.9205 - val_loss: 0.2493 - val_acc: 0.9190 Epoch 14/30 100/100 [==============================] - 12s 124ms/step - loss: 0.3376 - acc: 0.9210 - val_loss: 0.2341 - val_acc: 0.9250 Epoch 15/30 100/100 [==============================] - 12s 124ms/step - loss: 0.2221 - acc: 0.9330 - val_loss: 0.2193 - val_acc: 0.9320 Epoch 16/30 100/100 [==============================] - 12s 124ms/step - loss: 0.2211 - acc: 0.9435 - val_loss: 0.2471 - val_acc: 0.9240 Epoch 17/30 100/100 [==============================] - 12s 125ms/step - loss: 0.2864 - acc: 0.9295 - val_loss: 0.2287 - val_acc: 0.9180 Epoch 18/30 100/100 [==============================] - 13s 125ms/step - loss: 0.4689 - acc: 0.9330 - val_loss: 0.2699 - val_acc: 0.9280 Epoch 19/30 100/100 [==============================] - 12s 124ms/step - loss: 0.7805 - acc: 0.9370 - val_loss: 0.2119 - val_acc: 0.9270 Epoch 20/30 100/100 [==============================] - 12s 124ms/step - loss: 0.1596 - acc: 0.9455 - val_loss: 0.2715 - val_acc: 0.9190 Epoch 21/30 100/100 [==============================] - 12s 124ms/step - loss: 0.1700 - acc: 0.9505 - val_loss: 0.3470 - val_acc: 0.9230: 0.1744 - acc: 0. Epoch 22/30 100/100 [==============================] - 12s 124ms/step - loss: 0.3915 - acc: 0.9530 - val_loss: 0.4070 - val_acc: 0.9000 Epoch 23/30 100/100 [==============================] - 12s 124ms/step - loss: 0.1556 - acc: 0.9575 - val_loss: 0.2445 - val_acc: 0.9310 Epoch 24/30 100/100 [==============================] - 12s 124ms/step - loss: 0.1766 - acc: 0.9615 - val_loss: 0.3617 - val_acc: 0.9070 Epoch 25/30 100/100 [==============================] - 12s 124ms/step - loss: 0.1493 - acc: 0.9645 - val_loss: 0.3867 - val_acc: 0.9140 Epoch 26/30 100/100 [==============================] - 12s 124ms/step - loss: 0.1547 - acc: 0.9625 - val_loss: 0.3654 - val_acc: 0.9200 Epoch 27/30 100/100 [==============================] - 13s 126ms/step - loss: 0.1465 - acc: 0.9615 - val_loss: 0.6785 - val_acc: 0.9090 Epoch 28/30 100/100 [==============================] - 12s 124ms/step - loss: 0.1355 - acc: 0.9670 - val_loss: 0.9862 - val_acc: 0.9200 Epoch 29/30 100/100 [==============================] - 12s 124ms/step - loss: 0.1554 - acc: 0.9665 - val_loss: 0.3967 - val_acc: 0.9360 Epoch 30/30 100/100 [==============================] - 12s 123ms/step - loss: 0.2725 - acc: 0.9690 - val_loss: 0.4907 - val_acc: 0.9110 |
import matplotlib.pyplot as plt
acc = h5.history["acc"]
val_acc = h5.history["val_acc"]
plt.plot(range(1, len(acc)+1), acc, label="train_acc")
plt.plot(range(1, len(acc)+1), val_acc, label="test_acc")
plt.legend()out :

728x90
반응형
'K-디지털 빅데이터 분석서비스 개발자과정 20.11.02~21.04.12 > PYTHON(웹크롤링, 머신·딥러닝)' 카테고리의 다른 글
| 21.03.08. 딥러닝 - RNN 단어 철자 예측 및 뉴스기사 데이터 실습 (0) | 2021.03.08 |
|---|---|
| 21.03.05. 딥러닝 - 동물 이미지 인식, 패션 이미지 분류 (0) | 2021.03.05 |
| 21.03.03. 딥러닝 - 숫자손글씨 인식 마지막, 개고양이 인식 (1) | 2021.03.03 |
| 21.03.02. 딥러닝 - (0) | 2021.03.03 |
| 21.02.17. 딥러닝 - (0) | 2021.02.17 |
'K-디지털 빅데이터 분석서비스 개발자과정 20.11.02~21.04.12/PYTHON(웹크롤링, 머신·딥러닝)' Related Articles
more




Comments