
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 실행중인 포트 죽이기
- time wait port kill
- 티스토리챌린지
- window netstat time wait 제거
- 오블완
- conda base 기본 설정
- conda base 활성화
- conda 기초 설정
- conda 가상환경 설정 오류
- 3000 port kill
- 려려
- Today
- Total
모도리는 공부중
21.03.03. 딥러닝 - 숫자손글씨 인식 마지막, 개고양이 인식 본문
21.03.03. 딥러닝 - 숫자손글씨 인식 마지막, 개고양이 인식
공부하는 모도리 2021. 3. 3. 18:37



아래는 특허도 나온 것이라고 한다.
신경망 cnn구조




maxpooling

flatten


학습

손글씨 데이터를 마무리짓고 개, 고양이로 넘어갑시다.
과대적합 방지 - Dropout 함수 활용

드롭아웃은 학습을 하는 동안에만 적용되고 학습이 종료된 후 예측을 하는 단계에서는 모든 유닛을 사용하여 예측한다.

- 노드가 많아지거나 층이 많아진다고 해서 학습이 무조건 좋아진다고 볼 수 없음 → 과적합
- 과적합을 해결하는 가장 좋은 방법 → Drop out (은닉층에 배치된 노드 중 일부를 사용하지 않게 하는 방법)

from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout
# Conv2D : 컨볼루션 연산을 수행하는 층
# Flatten : CNN에서 처리한 특성맵을 1차원으로 변환
# 분류기에 넣기 위해서는 1차원으로 변환해야하기 때문
from tensorflow.keras.layers import Conv2D, Flatten
from tensorflow.keras.layers import MaxPooling2D
model4 = Sequential()
# CNN 층 (입력층)
# filters : 필터 수 (출력 수)
# kenel_size : 필터의 크기 (3x3, 5x5)
# input_shape : 입력 데이터의 크기 (2차원 이상인 경우 사용)
# padding : 패딩 여부를 설정 (same (패딩 수행), valid)
# strids : 필터가 이동하는 크기
# - strids를 크게하면 특성맵이 작아지는 효과
model4.add(Conv2D(filters=32, kernel_size=(3, 3),
input_shape=(28, 28, 1),
padding = "same",
strides = 1,
activation="relu"))
model4.add(Conv2D(filters=64, kernel_size=(3, 3),
padding = "same",
activation="relu"))
# 특성맵을 1차원으로 변환
model4.add(Flatten())
# 은닉층
model4.add(Dense(units=128, activation="relu"))
# 출력층
model4.add(Dense(10, activation="softmax"))
# 신경망 구조 출력
model4.summary()
dense층의 차이가 크므로 과대적합을 줄이기 위해 드롭아웃을 적용한다.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout
# Conv2D : 컨볼루션 연산을 수행하는 층
# Flatten : CNN에서 처리한 특성맵을 1차원으로 변환
# 분류기에 넣기 위해서는 1차원으로 변환해야하기 때문
from tensorflow.keras.layers import Conv2D, Flatten
from tensorflow.keras.layers import MaxPooling2D
model4 = Sequential()
# CNN 층 (입력층)
# filters : 필터 수 (출력 수)
# kenel_size : 필터의 크기 (3x3, 5x5)
# input_shape : 입력 데이터의 크기 (2차원 이상인 경우 사용)
# padding : 패딩 여부를 설정 (same (패딩 수행), valid)
# strids : 필터가 이동하는 크기
# - strids를 크게하면 특성맵이 작아지는 효과
model4.add(Conv2D(filters=32, kernel_size=(3, 3),
input_shape=(28, 28, 1),
padding = "same",
strides = 1,
activation="relu"))
model4.add(Conv2D(filters=64, kernel_size=(3, 3),
padding = "same",
activation="relu"))
# 특성맵을 1차원으로 변환
model4.add(Flatten())
# 은닉층
model4.add(Dense(units=128, activation="relu"))
# Dropout : 일단 summary를 먼저 돌리고 앞층과 뒤층의 차이가 많이 날 때 사용
# - 주로 입력층에 사용이 된다.
model4.add(Dropout(0.5))
# 출력층
model4.add(Dense(10, activation="softmax"))
# 신경망 구조 출력
model4.summary()

그래프까지 그려서 확인해보면 과대적합이 많이 잡힌 것을 비교할 수 있다. 이처럼 과대적합이 발생된다면 신경망 summary를 확인하여 파라미터수가 많이 차이나는 위치에 드롭아웃을 적용하였을 때 과대적합을 많이 잡아주는 것을 확인할 수 있다.


데이터 확장
- 과대적합이 일어나는 이유 중 하나는 훈련데이터가 부족하기 때문이다
- 훈련 데이터가 충분히 많다면 과대적합을 줄일 수 있다 .
- 데이터 확장이라 훈련 데이터를 다양하게 변형하여 변형된 새로운 훈련 데이터처럼 사용함으로써 마치 훈련 데이터 수가 늘어난 효과를 얻는 것이다 .


사용할 폴더를 설정
import os
base_dir = "./data/dogs_vs_cats_small2"
train_dir = os.path.join(base_dir, "train")
test_dir = os.path.join(base_dir, "test")
validation_dir = os.path.join(base_dir, "validation")
train_cats_dir = os.path.join(train_dir, "cats")
train_dogs_dir = os.path.join(train_dir, "dogs")
test_cats_dir = os.path.join(test_dir, "cats")
test_dogs_dir = os.path.join(test_dir, "dogs")
validation_cats_dir = os.path.join(validation_dir, "cats")
validation_dogs_dir = os.path.join(validation_dir, "dogs")# 각 폴더에 있는 파일의 개수를 출력
print("훈련용 고양이 데이터 개수 : ", len(os.listdir(train_cats_dir)))
print("훈련용 개 데이터 개수 : ", len(os.listdir(train_dogs_dir)))
print("테스트용 고양이 데이터 개수 : ", len(os.listdir(test_cats_dir)))
print("테스트용 개 데이터 개수 : ", len(os.listdir(test_dogs_dir)))
print("검증용 고양이 데이터 개수 : ", len(os.listdir(validation_cats_dir)))
print("검증용 개 데이터 개수 : ", len(os.listdir(validation_dogs_dir)))out :

이미지 전처리
- 0과 1사이 범위로 값을 반환
- 현재 입력 이미지들의 크기가 다 다름 → 동일한 크기로 반환
- 라벨링
# 이미지 처리용 라이브러리
from tensorflow.keras.preprocessing.image import ImageDataGenerator # 전처리
# 0~1 사이값으로 픽셀값을 변환
train_datagen = ImageDataGenerator(rescale=1./255)
test_datagen = ImageDataGenerator(rescale=1./255)
# 이미지 전처리
# 폴더에 있는 이미지를 전처리
train_generator = train_datagen.flow_from_directory(
# 폴더명
train_dir,
# 이미지 크기를 동일한 크기로 변환
target_size = (150, 150),
# 한 번에 전처리할 이미지의 수
batch_size = 20,
# 라벨링 : binary 이진라벨링, categorical 다중라벨링
# 라벨링 방법 : 폴더명의 첫 문자의 알파벳으로 0부터 부여
class_mode = "binary"
)
test_generator = test_datagen.flow_from_directory(
# 폴더명
validation_dir,
# 이미지 크기를 동일한 크기로 변환
target_size = (150, 150),
# 한 번에 전처리할 이미지의 수
batch_size = 20,
# 라벨링 : binary 이진라벨링, categorical 다중라벨링
# 라벨링 방법 : 폴더명의 첫 문자의 알파벳으로 0부터 부여
class_mode = "binary"
)out :
Found 200 images belonging to 2 classes.
Found 100 images belonging to 2 classes.
print(train_generator.class_indices)
print(test_generator.class_indices)out :
{'cats': 0, 'dogs': 1}
{'cats': 0, 'dogs': 1}
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Flatten
from tensorflow.keras.layers import Conv2D, MaxPooling2D
model1 = Sequential()
model1.add(Conv2D(filters=32, kernel_size=(3, 3), input_shape=(150, 150, 3), padding="same", activation="relu"))
model1.add(MaxPooling2D(pool_size=(2, 2)))
model1.add(Flatten())
model1.add(Dense(units=512, activation="relu"))
model1.add(Dense(units=1, activation="sigmoid"))
model1.summary()
특성의 개수가 75개로 너무 많이 있으니 maxpooling을 통해 줄여준다.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Flatten
from tensorflow.keras.layers import Conv2D, MaxPooling2D
model1 = Sequential()
model1.add(Conv2D(filters=32, kernel_size=(3, 3), input_shape=(150, 150, 3), padding="same", activation="relu"))
model1.add(MaxPooling2D(pool_size=(2, 2)))
model1.add(Conv2D(filters=32, kernel_size=(3, 3), input_shape=(150, 150, 3), padding="same", activation="relu"))
model1.add(MaxPooling2D(pool_size=(2, 2)))
model1.add(Conv2D(filters=32, kernel_size=(3, 3), input_shape=(150, 150, 3), padding="same", activation="relu"))
model1.add(MaxPooling2D(pool_size=(2, 2)))
model1.add(Conv2D(filters=32, kernel_size=(3, 3), input_shape=(150, 150, 3), padding="same", activation="relu"))
model1.add(MaxPooling2D(pool_size=(2, 2)))
model1.add(Flatten())
model1.add(Dense(units=512, activation="relu"))
model1.add(Dense(units=1, activation="sigmoid"))
model1.summary()
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Flatten
from tensorflow.keras.layers import Conv2D, MaxPooling2D
model1 = Sequential()
model1.add(Conv2D(filters=32, kernel_size=(3, 3), input_shape=(150, 150, 3), padding="same", activation="relu"))
model1.add(MaxPooling2D(pool_size=(2, 2)))
model1.add(Conv2D(filters=64, kernel_size=(3, 3), input_shape=(150, 150, 3), padding="same", activation="relu"))
model1.add(MaxPooling2D(pool_size=(2, 2)))
model1.add(Conv2D(filters=128, kernel_size=(3, 3), input_shape=(150, 150, 3), padding="same", activation="relu"))
model1.add(MaxPooling2D(pool_size=(2, 2)))
model1.add(Conv2D(filters=256, kernel_size=(3, 3), input_shape=(150, 150, 3), padding="same", activation="relu"))
model1.add(MaxPooling2D(pool_size=(2, 2)))
model1.add(Flatten())
model1.add(Dense(units=512, activation="relu"))
model1.add(Dense(units=1, activation="sigmoid"))
model1.summary()
model1.compile(loss="binary_crossentropy", optimizer="adam", metrics=["acc"])# generator : 제너레이터를 설정
h1 = model1.fit_generator(generator=train_generator, epochs=30, validation_data=test_generator)

import matplotlib.pyplot as plt
acc = h1.history["acc"]
val_acc = h1.history["val_acc"]
plt.plot(range(1, len(acc)+1), acc, label="train_acc")
plt.plot(range(1, len(acc)+1), val_acc, label="test_acc")
plt.legend()
훈련용과 검증용 개수를 각각 10배 늘려서 재시도해보자.
개수를 늘려서 재시도
import os
base_dir = "./data/dogs_vs_cats_small2_2/"
train_dir = os.path.join(base_dir, "train")
test_dir = os.path.join(base_dir, "test")
validation_dir = os.path.join(base_dir, "validation")
train_cats_dir = os.path.join(train_dir, "cats")
train_dogs_dir = os.path.join(train_dir, "dogs")
test_cats_dir = os.path.join(test_dir, "cats")
test_dogs_dir = os.path.join(test_dir, "dogs")
validation_cats_dir = os.path.join(validation_dir, "cats")
validation_dogs_dir = os.path.join(validation_dir, "dogs")
# 각 폴더에 있는 파일의 개수를 출력
print("훈련용 고양이 데이터 개수 : ", len(os.listdir(train_cats_dir)))
print("훈련용 개 데이터 개수 : ", len(os.listdir(train_dogs_dir)))
print("테스트용 고양이 데이터 개수 : ", len(os.listdir(test_cats_dir)))
print("테스트용 개 데이터 개수 : ", len(os.listdir(test_dogs_dir)))
print("검증용 고양이 데이터 개수 : ", len(os.listdir(validation_cats_dir)))
print("검증용 개 데이터 개수 : ", len(os.listdir(validation_dogs_dir)))out :
훈련용 고양이 데이터 개수 : 1000
훈련용 개 데이터 개수 : 1000
테스트용 고양이 데이터 개수 : 11
테스트용 개 데이터 개수 : 11
검증용 고양이 데이터 개수 : 500
검증용 개 데이터 개수 : 500
# 이미지 처리용 라이브러리
from tensorflow.keras.preprocessing.image import ImageDataGenerator # 전처리
# 0~1 사이값으로 픽셀값을 변환
train_datagen = ImageDataGenerator(rescale=1./255)
test_datagen = ImageDataGenerator(rescale=1./255)
# 이미지 전처리
# 폴더에 있는 이미지를 전처리
train_generator = train_datagen.flow_from_directory(
# 폴더명
train_dir,
# 이미지 크기를 동일한 크기로 변환
target_size = (150, 150),
# 한 번에 전처리할 이미지의 수
batch_size = 20,
# 라벨링 : binary 이진라벨링, categorical 다중라벨링
# 라벨링 방법 : 폴더명의 첫 문자의 알파벳으로 0부터 부여
class_mode = "binary"
)
test_generator = test_datagen.flow_from_directory(
# 폴더명
validation_dir,
# 이미지 크기를 동일한 크기로 변환
target_size = (150, 150),
# 한 번에 전처리할 이미지의 수
batch_size = 20,
# 라벨링 : binary 이진라벨링, categorical 다중라벨링
# 라벨링 방법 : 폴더명의 첫 문자의 알파벳으로 0부터 부여
class_mode = "binary"
)out :
Found 2000 images belonging to 2 classes.
Found 1000 images belonging to 2 classes.
print(train_generator.class_indices)
print(test_generator.class_indices)out :
{'cats': 0, 'dogs': 1}
{'cats': 0, 'dogs': 1}
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Flatten
from tensorflow.keras.layers import Conv2D, MaxPooling2D
model1 = Sequential()
model1.add(Conv2D(filters=32, kernel_size=(3, 3), input_shape=(150, 150, 3), padding="same", activation="relu"))
model1.add(MaxPooling2D(pool_size=(2, 2)))
model1.add(Conv2D(filters=64, kernel_size=(3, 3), input_shape=(150, 150, 3), padding="same", activation="relu"))
model1.add(MaxPooling2D(pool_size=(2, 2)))
model1.add(Conv2D(filters=128, kernel_size=(3, 3), input_shape=(150, 150, 3), padding="same", activation="relu"))
model1.add(MaxPooling2D(pool_size=(2, 2)))
model1.add(Conv2D(filters=256, kernel_size=(3, 3), input_shape=(150, 150, 3), padding="same", activation="relu"))
model1.add(MaxPooling2D(pool_size=(2, 2)))
model1.add(Flatten())
model1.add(Dense(units=512, activation="relu"))
model1.add(Dense(units=1, activation="sigmoid"))
model1.summary()
model1.compile(loss="binary_crossentropy", optimizer="adam", metrics=["acc"])
# generator : 제너레이터를 설정
h1 = model1.fit_generator(generator=train_generator, epochs=30, validation_data=test_generator)

import matplotlib.pyplot as plt
acc = h1.history["acc"]
val_acc = h1.history["val_acc"]
plt.plot(range(1, len(acc)+1), acc, label="train_acc")
plt.plot(range(1, len(acc)+1), val_acc, label="test_acc")
plt.legend()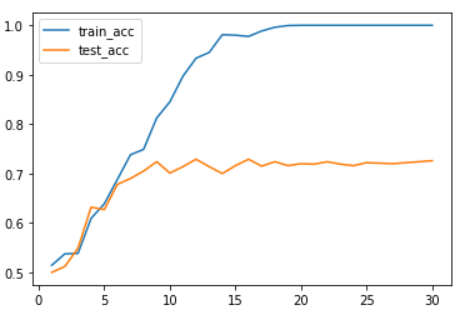
과대적합을 피하는 방법
데이터 확장
- rotation_ range = 360 : 0 에서 360 사이에서 회전
- width_shift_range = 0.1 : 전체에서 10% 내외 수평이동
- height_shift_range = 0.1 : 전체에서 10% 내외 수직이동
- shear_range = 0.5 : 0.5 라디안 내외 시계반대방향으로 변형
- zoom_range = 0.3 : 0.7~1.3 배로 축소 확대
- Horizontal_flip = True : 수평방향으로 뒤집기
- Vertical_flip = True : 수직방향으로 뒤집기


데이터 확장 (증식 : augmentation)
- 이미지를 변형시켜서 여러 개의 이미지로 만드는 것
- 이미지 변형 : 크기 변경, 이동, 회전, 찌그러뜨림 등
- 주의할 점 : 증식은 훈련데이터에만 사용
train_gen = ImageDataGenerator(
rescale = 1./255,
rotation_range = 20, # 너무 크게 바꾸지 않고 20도 범위내에서만 회전 변환
width_shift_range = 0.2, # 20% 범위에서 좌우 이동
height_shift_range = 0.2, # 20% 범위에서 상하 이동
shear_range = 0.1, # 10% 범위에서 기울임
zoom_range = 0.1, # 10% 범위에서 확대/축소
horizontal_flip = True, # 수평뒤집기
# 변형하면서 이미지가 깨지는 것을 보상
# 주변에 있는 범위 참고
fill_mode = "nearest"
)
test_gen = ImageDataGenerator(rescale = 1./255) train_generator2 = train_gen.flow_from_directory(
train_dir,
target_size = (150 , 150),
batch_size=20,
class_mode="binary"
)
test_generator2 = test_gen.flow_from_directory(
validation_dir,
target_size = (150 , 150),
batch_size=20,
class_mode="binary"
)model2.compile(loss="binary_crossentropy",
optimizer="adam",
metrics=["acc"])# generator : 설정한 제너레이터를 설정
h2 = model2.fit_generator(generator = train_generator2,
epochs = 18,
validation_data = test_generator2)

import matplotlib.pyplot as plt
acc = h2.history["acc"]
val_acc = h2.history["val_acc"]
plt.plot(range(1, len(acc)+1), acc, label="train_acc")
plt.plot(range(1, len(acc)+1), val_acc, label="test_acc")
plt.legend()
'K-디지털 빅데이터 분석서비스 개발자과정 20.11.02~21.04.12 > PYTHON(웹크롤링, 머신·딥러닝)' 카테고리의 다른 글
| 21.03.05. 딥러닝 - 동물 이미지 인식, 패션 이미지 분류 (0) | 2021.03.05 |
|---|---|
| 21.03.04. 딥러닝 - (0) | 2021.03.04 |
| 21.03.02. 딥러닝 - (0) | 2021.03.03 |
| 21.02.17. 딥러닝 - (0) | 2021.02.17 |
| 21.02.16. 딥러닝 - XOR논리(다중 퍼셉트론), 딥러닝 프레임워크, tqdm을 활용한 반복수 확인, 학습과정(fit()) 직접 구현 (0) | 2021.02.17 |



