
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- conda base 기본 설정
- 실행중인 포트 죽이기
- window netstat time wait 제거
- conda 기초 설정
- time wait port kill
- conda base 활성화
- 3000 port kill
- 려려
- 티스토리챌린지
- 오블완
- conda 가상환경 설정 오류
- Today
- Total
모도리는 공부중
21.02.17. 딥러닝 - 본문
21.02.17. 딥러닝 -
공부하는 모도리 2021. 2. 17. 15:49저번 시간 정리..

# 퍼셉트론 1개로 구성된 신경망
# 넘파이 임포트 안했다면 해줄것
# (특성 데이터, 라벨 데이터, 반복수, 학습률)
def fit_new(X, y, epochs, lr) :
# (1) 파라미터 초기화(w,b)
w = np.random.rand(1)
b = np.random.rand(1)
# epochs만큼 반복해서 학습
for i in range(epochs):
# (3) 입력받는 X를 이용해서 y를 예측 (예측값y = pred_y)
pred_y = w * X + b
# (4) 오차 계산 (오차error = 실제값y - 예측값pred_y)
error = y - pred_y
print("반복수 : {}, 예측값 : {}, 오차 : {}".format(i, pred_y, error))
# (5) 기울기 계산 (비용함수) : 오차error / 예측값pred_y 미분해준다.
d1 = error / pred_y
# (6) 기울기를 이용해서 w, b를 갱신 (학습)
# 기울기를 그냥 더해주면 파라미터값이 크게 변함
# 일정 비율만큼만 적용되도록 학습률 곱함
w = w + d1 * lr
b = b + d1 * lr한 번으로 이해가 잘 가지 않는다면 한 번 더 실습해보도록 합니다.

앞에서는 입력 하나 바이어스 하나 출력 하나인 이런 구조로 인해 역전파를 한 번만 했다면,

폐암 데이터셋을 이용한 딥러닝 이진분류
폐암 수술 환자의 생존율 예측 (종양유형 폐활량 흡연여부 천식여부 나이 등)
import pandas as pd
data = pd.read_csv("ThoraricSurgery.csv",header=None)
data.head()폐암 수술환자 데이터셋 (ThoraricSurgery.csv)
- 폴란드 브로츠와프 의과대학에서 2013년 공개한 폐암 수술 환자의 수술 전 데이터와 수술 후 생존결과를 기록한
의료 기록 데이터 - 18개 항목으로 구성된 470개의 데이터로 구성되고 각 항목은 쉼표(,)로 구분
- 종양 유형, 폐활량, 호흡곤란여부, 고통 정도, 기침, 흡연, 천식여부 등 17가지 환자 상태
- 18번째 항목은 수술 후 생존 결과 (1 : 생존 , 0 : 사망) ← 라벨데이터로 활용 가능

특성 데이터와 라벨 데이터 분리
X = data.iloc[:,:-1]
y = data.iloc[:,-1]
X.shape, y.shape
# X는 행렬이고, y는 행값만 있는 3D데이터
파라미터 초기화를 위한 seed 설정
- 같은 조건에서 신경망을 테스트하기 위해서
여기서 든 궁금증, seed 설정이 뭐죠? (교재 146쪽 참고)
- 랜덤 테이블 중에서 몇 번째 테이블을 불러와 사용할지를 정하는 것이다. 우리가 지금까지 배워왔던 것중에서 떠올린다면 random_state와 같은 역할을 하는 것으로 추정된다.
import numpy as np
import tensorflow as tf
seed = 999
# 항상 같은 값으로 파라미터가 초기화
np.random.seed(seed)
tf.random.set_seed(seed)코드를 보면 numpy뿐만 아니라 tensorflow도 똑같은 seed로 설정해준 것을 알 수 있다. 딥러닝을 구현할 때 일정한 결과값을 얻기 위한 것이며, 이렇게 똑같이 설정해주어도 출력값은 미세하게 다를 수 있다고 한다. 이는 텐서플로우 자체 랜덤테이블 문제이므로 최종 딥러닝 결과를 여러 번 실행하여 평균을 구하는 것이 가장 적절하다.
이진 분류를 위한 신경망 설계
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
model1 = Sequential()
# 입력층
model1.add(Dense(units=?, input_dim=?, activation=?))
# 은닉층
model1.add(Dense(units=?, activation=?))
# 출력층
model1.add(Dense(units=?, activation=?))
model1.summary()↑물음표를 직접 채워보세요.
우리가 지금까지 배우면서 사용된 용어들의 설명. 내가 궁금하고 이해가 잘 안 가서 책과 pdf를 뒤져보며 정리했다. 필요하다면 더보기를 눌러서 확인해도 좋다. 이미 모두 이해하고 있다면 그냥 넘어가도록.
딥러닝 설계 단계에 사용되는 함수 - Sequential(), add(), Dense(), Activation()
Sequential() - 교재 130쪽 참고
- 케라스에 있는 함수, 이 함수를 model로 선언하고 model.add()라는 라인을 추가하면 새로운 층이 추가된다.
- 신경망을 한 층, 한 층 쌓는 기능
add() - 신경망 층을 추가
Dense() - 교재 131쪽 참고
- '조밀하게 모여있는 집합'이라는 뜻으로 실제 신경망 층을 설정하는 기능을 담당.
- 각 층이 제각각 어떤 특성을 가질지 옵션을 설정하는 역할. 구체적으로 구조를 결정한다.
Activation()
- 가중합의 결과 0과 1을 판단하는 함수. 결과를 판단하여 다음 층으로 값을 보내준다.
- 가중합? - 입력값(x)과 가중치(w)의 곱을 모두 더한 다음 바이어스(b)를 더한 값을 의미.
- y = w * x + b인 선형모델을 의미한다.
- 활성화 함수 : 출력으로 나오게 하는 기준값 (sigmoid, tanh, relu, softmax 등)
compile() 함수 - 단어 그대로 컴퓨터가 알아들을 수 있는 언어로 컴파일해주는 역할.
summary() 함수 - 신경망 구조 확인. 영수증 같은 출력값을 보여준다.
딥러닝은 layer라는 층을 차곡차곡 쌓아가며 만든다. 라인을 2개만 사용했다면 입력층과 출력층만 사용한 것이며 다(多)층으로 구성되었다면 맨 윗층은 입력, 마지막 라인은 출력층이며 나머지는 모두 은닉층의 역할을 한다. 책에서는 출력층을 제외한 모든 층이 은닉층이라고 설명하고 있으며 첫번째 Dense가 은닉층+입력층의 역할을 겸한다고 설명하고 있다.
input_dim 변수 : 입력 데이터에서 몇 개의 값을 가져올지 정한다. 첫 시간에 우리는 이것을 입력개수(특성수)라고 배웠다.
활성화 함수 파고들기 - 교재 120쪽 참고
활성화함수는 앞에서 적었듯이 sigmoid, tanh, relu, softmax 등이 있다. 이중에서 지금까지는 sigmoid와 relu를 사용했으며 오늘 중으로 softmax까지 사용할 것이다(21년 2월 17일 기준). 그럼 이것들은 대체 무엇일까?
sigmoid - 교재 90쪽 참고 (88쪽부터 다시 읽으면서 정리할 것) - 아직 정리중입니다.-
채우셨다면 진도를 나가봅시다.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
model1 = Sequential()
# 입력층 (데이터(원 특성)를 입력받는 층)
model1.add(Dense(units=34, input_dim=17, activation="relu")) # units은 자유롭게 작성.
# 은닉층 (특성을 추출하는 층)
model1.add(Dense(units=17, activation="relu"))
# 파이프라인 특성으로 input_dim은 자동으로 붙는다. units은 자유롭게 작성.
# 출력층 (결과(라벨)를 출력하는 층)
# 회귀 : units=1, activation="linear" 또는 units=1
# - 이렇게 적으면 그대로 꺼내준다.
# 다중분류 : units=y의 수, activation="softmax"
# 이진분류1 : units=1, activation="sigmoid"
# - y가 하나이므로 sigmoid
# 이진분류2 : units=2, activation="softmax"
# - y가 두개이므로 softmax
model1.add(Dense(units=1, activation="sigmoid"))
# 여기서 units는 y개수를 적는다.
model1.summary()out :

위 결과에 대한 해설

신경망 컴파일
model1.compile(loss="binary_crossentropy", optimizer="adam", metrics=["acc"])학습
h = model1.fit(X, y, epochs=100, batch_size=20)오류가 났다면 더보기를 열어보시고, 그렇지 않다면 결과를 바로 확인하세요.
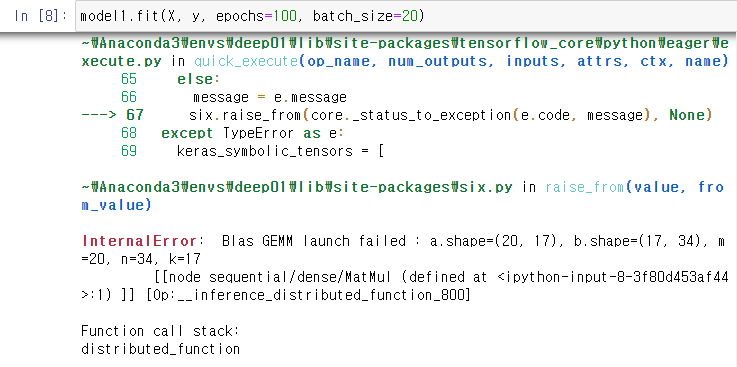
위처럼 오류가 났다면 메모리 오류가 난 경우이므로 작업관리자를 확인해보도록 한다.
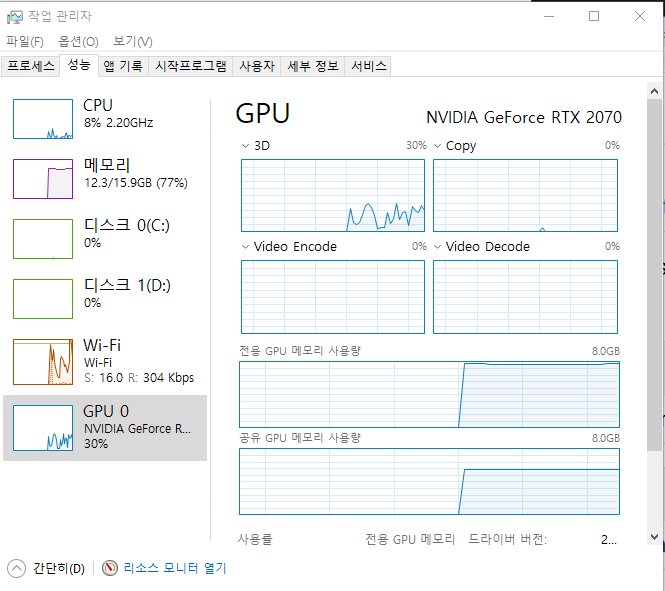
gpu메모리가 가득 찬 상태. 이게 다운되어 있어야한다고.
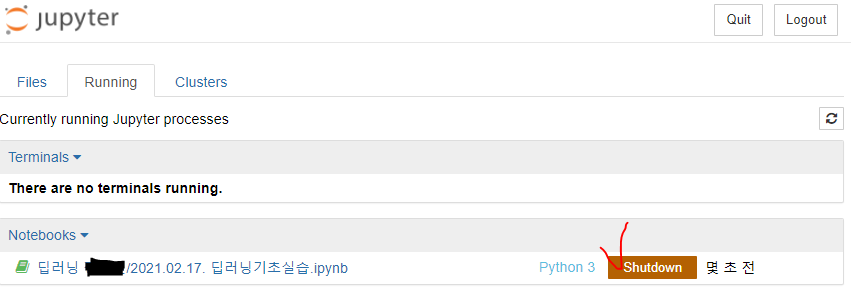
노트북에서 셧다운을 해준다.
이것저것 다 꺼보아도 남아있다면 재부팅을 하고 옵시다.
out :

결과 시각화
import matplotlib.pyplot as plt
acc = h.history["acc"]
x = range(1,101)
plt.plot(x,acc)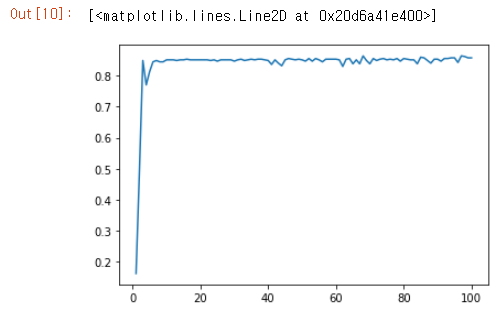
자, 이제 최대값을 90으로 만들어봅시다. (실습)
내 데이터는 units을 60, 30으로 바꾸고 epochs를 1500으로 바꾼 결과 0.94까지 나오게 되었다.

위 결과에 대해 코드를 자세히 보고 싶다면 아래의 더보기를 열어주세요.
seed = 999
# 항상 같은 값으로 파라미터가 초기화
np.random.seed(seed)
tf.random.set_seed(seed)
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
model1 = Sequential()
# 입력층 (데이터(원 특성)를 입력받는 층)
model1.add(Dense(units=60, input_dim=17, activation="relu")) # units은 자유롭게 작성.
# 은닉층 (특성을 추출하는 층)
model1.add(Dense(units=30, activation="relu"))
# 파이프라인 특성으로 input_dim은 자동으로 붙는다. units은 자유롭게 작성.
# 출력층 (결과(라벨)를 출력하는 층)
# 회귀 : units=1, activation="linear" 또는 units=1
# - 이렇게 적으면 그대로 꺼내준다.
# 다중분류 : units=y의 수, activation="softmax"
# 이진분류1 : units=1, activation="sigmoid"
# - y가 하나이므로 sigmoid
# 이진분류2 : units=2, activation="softmax"
# - y가 두개이므로 softmax
model1.add(Dense(units=1, activation="sigmoid"))
# 여기서 units는 y개수를 적는다.
model1.summary()
model1.compile(loss="binary_crossentropy", optimizer="adam", metrics=["acc"])
h = model1.fit(X, y, epochs=1500, batch_size=20)
# 결과는 아까 사진으로 빼꼼했음
import matplotlib.pyplot as plt
acc = h.history["acc"]
x = range(1,1501)
plt.plot(x,acc)
plt.ylim(0,1)과대적합 확인
# 훈련데이터와 테스트데이터로 분리
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)h2 = model1.fit(X_train, y_train, epochs=1000, batch_size=20, validation_data=(X_test, y_test))out :


import matplotlib.pyplot as plt
acc = h2.history["acc"]
val_acc = h2.history["val_acc"]
x1 = range(1, 1001)
plt.plot(x1, acc, label="train")
plt.plot(x1, val_acc, label="test")
plt.ylim(0,1)
plt.legend()
아래는 그래프에 대한 선생님의 설명 그림.

이진 분류 - y를 원핫인코딩해서 학습
y_en = pd.get_dummies(y)
y_en.shapeout : (470, 2)
model3 = Sequential()
# 입력층
model3.add(Dense(34, input_dim=X.shape[1], activation="relu"))
# 은닉층
model3.add(Dense(17, activation="relu"))
# 출력층
model3.add(Dense(y_en.shape[1], activation="softmax"))
# softmax함수는 확률값으로 나온다.
model3.summary()input_dim을 숫자로 바로 넣지 않고 shape를 이용하면 값을 내가 기억해서 집어넣지 않아도 되므로 편리하다.

model3.compile(loss="binary_crossentropy", optimizer="adam", metrics=["acc"])
h3 = model3.fit(X, y_en, epochs=100, batch_size=10)out :


acc = h3.history["acc"]
x1 = range(1, 101)
plt.plot(x1, acc, label="train")
plt.ylim(0,1)
plt.legend()
y를 원핫인코딩한 상태에서 softmax를 사용했을 때 값이 0.0000으로 나오는 경우가 생길 수도 있다. 학습이 안되는 현상이 일어난 것인데, 이는 수학적인 문제로 추측된다. 그런 경우에는 loss를 categorical_crossentropy로 바꿔주고 다시 컴파일해보도록 한다.
# binary_crossentropy를 사용하면 값이 잘 안 나올 수 있다.
# 이진분류라도 softmax를 사용한 경우라면 loss를 categorical_crossentropy로 사용
model3.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["acc"])

acc = h3.history["acc"]
x1 = range(1, 101)
plt.plot(x1, acc, label="train")
plt.ylim(0,1)
plt.legend()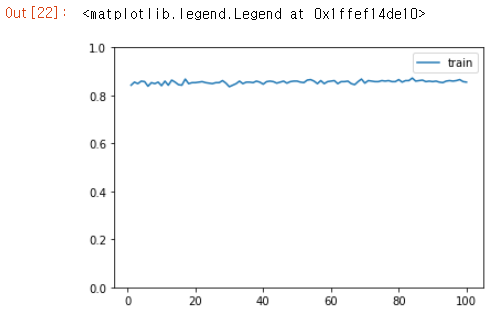
아래 그래프는 입력, 은닉, 출력층 있는 부분부터 다시 돌리니까 또 값이 달라진 상태이다. 분명 비슷은 한데 뭔가 값이 다르게 나오고 있다.

위 그림의 학습시키는 과정이 궁금하다면 더보기를 눌러주세요.


softmax에 대한 추가 궁금증. 교재 99쪽과 155쪽에 나와있다. 마침 우리가 수업중인 iris 데이터를 활용하는 예제도 있으니 참고하면 좋을 듯하다.
softmax는 입력값이 추가되어서 세 개 이상의 입력값을 다루는 경우에 사용하는 함수라고 한다. 최종 출력 값이 3개 중 하나여야 할 경우 출력층의 Dense의 노트 수(units)를 3으로 설정(이것은 간편하게 y_en.shape[1]로 대체하였다.)하고 activation을 softmax로 입력한다.
'K-디지털 빅데이터 분석서비스 개발자과정 20.11.02~21.04.12 > PYTHON(웹크롤링, 머신·딥러닝)' 카테고리의 다른 글
| 21.03.03. 딥러닝 - 숫자손글씨 인식 마지막, 개고양이 인식 (1) | 2021.03.03 |
|---|---|
| 21.03.02. 딥러닝 - (0) | 2021.03.03 |
| 21.02.16. 딥러닝 - XOR논리(다중 퍼셉트론), 딥러닝 프레임워크, tqdm을 활용한 반복수 확인, 학습과정(fit()) 직접 구현 (0) | 2021.02.17 |
| 21.02.15. 딥러닝 - 주피터 노트북 환경설정, 이론(뉴런, 시냅스, …), AND·OR·XOR논리 (0) | 2021.02.15 |
| 21.01.14. 머신러닝 - 텍스트마이닝 두 번째 시간 (0) | 2021.01.14 |



