

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- conda 기초 설정
- conda 가상환경 설정 오류
- 티스토리챌린지
- conda base 활성화
- window netstat time wait 제거
- 실행중인 포트 죽이기
- 려려
- time wait port kill
- 3000 port kill
- 오블완
- conda base 기본 설정
- Today
- Total
모도리는 공부중
21.01.14. 머신러닝 - 텍스트마이닝 두 번째 시간 본문
21.01.14. 머신러닝 - 텍스트마이닝 두 번째 시간
공부하는 모도리 2021. 1. 14. 13:29저번시간에 다운로드한 영화리뷰데이터를 이용해서 오늘 수업 진행합니다.

앞 번호는 몇번 리뷰인지 알려주는 번호, 뒤 번호는 평점. 1~4점까지는 부정 리뷰라고 생각하여 부정폴더(neg)에 모두 모아놨다.

마찬가지. 대신 여기는 10~7점까지 긍정리뷰라고 판단하여 긍정폴더(pos)에 모두 모아놨다.
그렇다면 5,6점은 어디로 간걸까? - 애매한 판단. 긍정인지 부정인지 판단하기 어려운 평점이기 때문에 이 점수는 제외하고 뚜렷한 평가가 나타나는 점수만을 모아서 하는 것이 평가를 내릴 때 적합하다.
실제로는 판단 기준에 따라 5,6점도 필요할 수 있다. 하지만 오늘 수업할 부분은 실습 목표에 적합한 부분만 모았기 때문에 이처럼 빠지고 제외된 부분이 몇몇 있을 수 있으니 참고.
폴더 순서에 맞춰서 0번, 1번 이렇게 번호가 자동으로 매겨지니 기억하도록 하자.
자, 이제 주피터노트북을 실행하여 코드를 작성하며 수업을 진행해봅시다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt필요한 라이브러리를 먼저 import.
1. 문제정의
- 영화리뷰, 데이터셋을 활용해 긍정리뷰와 부정리뷰를 구분하는 모델을 만들자.
- 긍정/부정 리뷰에서 자주 사용되는 단어를 시각화해보자.
2. 데이터수집
- IMDB 데이터 셋 활용
# 사이킷런에 보면 데이터셋이라는게 있고 그 안에 로드파일이 있다.
# 이걸 이용하면 폴더 안에 파일을 순차적으로 읽어서 가져와주는 역할을 한다.
# 폴더 순서대로 0, 1, 2 이렇게 라벨링하여 불러옴.
from sklearn.datasets import load_files
train_data_url = "aclImdb/train/"
reviews_train = load_files(train_data_url, shuffle=True)train data를 해줬으니 똑같이 test data도 해주도록 하자.
test_data_url = "aclImdb/test/"
reviews_test = load_files(test_data_url, shuffle=True)각각 불러오는데 시간이 조금 걸린다. 좋은 성능의 컴퓨터라면 1분 내외로 끝날 것이다.
(머신러닝할 컴퓨터가 성능이 좋아야 하는 이유이기도 하다.)
reviews_train
# 타입을 확인해보자
type(reviews_train)
# 사이킷런으로 불러왔기 때문에 사이킷런에서 만든 딕셔너리인 Bunch로 불러와진 것을 확인할 수 있다.reviews_train.keys()out : dict_keys(['data', 'filenames', 'target_names', 'target', 'DESCR'])
# 리뷰를 5건 정도 불러와보자.
reviews_train.data[:5]
# 보기 편하게 데이터프레임형식으로 호출
reviews_df = pd.DataFrame(reviews_train.data)
reviews_df
reviews_train.target[:5]
# 학습을 잘할 수 있도록 긍정리뷰와 부정리뷰의 비율을 맞춰놓았음out : array([1, 0, 1, 0, 0])
reviews_df.info()out :

np.bincount(reviews_train.target)
# bincount를 사용하면 0이 몇개, 1이 몇개 이렇게 세주는 역할을 한다.out : array([12500, 12500], dtype=int64)
- 데이터를 일반화하는 방법은 2가지가 있다.
- 데이터적인 부분을 일반화
- 데이터를 어떻게 하면 일반화가 잘된다고 배웠나요?
- 데이터 수가 많으면 많을수록 일반화가 잘됩니다.
- 영화리뷰데이터를 왜 긍정 반, 부정 반 나눴을까요? - 데이터의 밸런스.
- 데이터의 밸런스를 맞춰서 양쪽을 다 잘 맞힐 수 있도록.
- 어느 한쪽의 데이터양이 많을수록 그쪽의 학습량이 많아서 적중률이 떨어진다.
- 데이터를 어떻게 하면 일반화가 잘된다고 배웠나요?
- 모델을 일반화
- 데이터적인 부분을 일반화
3. 데이터 전처리
- 일반 정형화된 데이터 : 결측치, 스케일링, 특성공학, 이상치, ……
- 텍스트 데이터(비정형 데이터)
- 오탈자 제거
- 띄어쓰기 교정
- 이모티콘 수정
- 불필요한 글자 제거(불용어)
- 데이터 정형화 : 토큰화, 수치화
# br태그 제거
text_train = [ txt.replace(b"<br />",b" ") for txt in reviews_train.data ]
# 리스트내포를 사용하여 한줄로 정리한 코드.
# replace : 교체하겠다. b"<br />"를 b" "로 교체해주겠다.
# 코드 앞에 있는 b는 뭔가요? : binary형태라는 의미.
# 문자열을 표현해서 저장할 때 binary형태로 저장해서 관리하라고 알려주는 역할.train처럼 test도 br태그 제거
text_test = [ txt.replace(b"<br />",b" ") for txt in reviews_test.data ]잘 잘라졌는지 각각의 0번을 호출
text_train[0]
text_test[0]
정형화를 해보도록 합시다. 정형화할 수 있는 코드들 중에 BOW를 사용합니다.
BOW ( Bag of Word )
from sklearn.feature_extraction.text import CountVectorizer
# 사이킷런에서 feature특성을 extraction추출한다tmp_vect = CountVectorizer()# 말뭉치 생성
sample_text = ["어제 저녁에는 공기밥을 두 개 먹었다.",
"어제 저녁에 봤던 영화는 너무 재미있었다.",
"이런 영화를 돈주고 봐야하다니.. 안타깝다..."]
# 3개의 문서를 샘플로 만듦.# 토큰화 -> 단어사전
tmp_vect.fit(sample_text)
# 띄어쓰기 기준으로 토큰화시켜서 중복되는 것을 없앤다.
# 띄어쓰기 중심으로 진행할 때 두 글자 이상인 것만 추출하도록 되어있는 방식.
# 한 글자만 작성했다면 그 글자는 추출에 실패할 수 있다.out : CountVectorizer()
최신버전인 우리는 결과가 CountVectorizer() 이것으로 끝난다. 상세한 결과가 나오지 않기 때문에 선생님 화면 캡쳐본으로 설명 첨부.
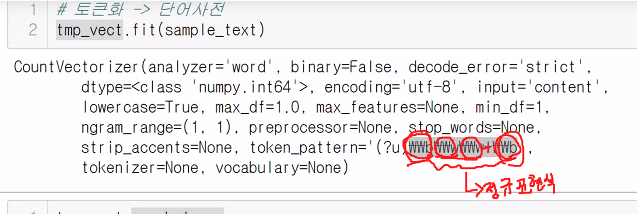
tmp_vect.vocabulary_
# 잘라진 토큰들은 문장 순서가 의미 없어진다.
# 그렇기 때문에 나열된 토큰을 가나다라 순으로 넘버 라벨링을 해준다.
# 수치화
tmp_vect.transform(sample_text)
이 결과를 풀어쓰면 아까 출력된 것을 가져와서 설명할 수 있다.

등장하지 않는 데이터는 0으로 표현, 등장한 데이터만 1로 표현해서 규격화된 형태로 정형화시켜준다.
이렇게 14개의 feature로 표현. 원핫인코딩과 굉장히 흡사하다.
0이 들어간 부분은 어차피 우리에게 필요가 없다. 이런 부분을 압축시켜서 사용하는 것이 바로 sparse matrix of type. 희소행렬이라고 한다. 이 압축된 것을 굳이 보고 싶다면? toarray사용.
tmp_vect.transform(sample_text).toarray()
이것을 보고 단어사전을 다시 보면 이게 어떤 문장인지 볼 수 있다.
지금은 학습중이기 때문에 데이터가 많지 않아서 이렇게 toarray를 사용해서 직접 볼 수 있지만, 실제 사용할 때는 toarray를 사용하게 되면 너무 많은 양의 데이터를 불러오고 알아보기도 어려우므로 사용하지 않는 것을 권한다.
영화 리뷰에 BOW 적용하기
movie_vect = CountVectorizer()
movie_vect.fit(text_train)out : CountVectorizer()
len(movie_vect.vocabulary_)out : 74849

# transform해서 정형화된 데이터로 변환
X_train = movie_vect.transform(text_train)
X_test = movie_vect.transform(text_test)# 안하고 넘어간 것 같네요? 이것도 해줍시다.
y_train = reviews_train.target
y_test = reviews_test.target
4. 모델 선택
긍정이나 부정을 분류하는 선형모델 분석을 진행중이므로 LogisticRegression 진행.
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score # 교차검증교차검증을 하는 이유?
- 테스트 적용 전에 트레인 데이터 학습이 일반화 됐는지 보기 위해서.
교차검증은 데이터 셋을 여러 번 쪼개서 학습과 평가를 여러 번 한다.
- 일부러 여러 개의 데이터가 들어오는 것처럼 교차 검증을 줘서 평균을 내면 데이터가 오락가락하더라도 평균으로 평가 내릴 수 있는 점수가 나오게 된다.
- 데이터셋이 적을 때는 교차검증의 효과가 뛰어나다.
- 데이터셋이 많아지면 교차검증 효과가 떨어진다.
- 데이터가 많으면 어차피 일반화 유도가 되는 관계로 교차검증을 하지 않더라도 괜찮기 때문.
딥러닝에서는 어차피 데이터가 많이 필요로 하기 때문에 교차검증을 잘 진행하지 않는다. 하지만 일반적인 테이블 데이터를 다룰 때는 데이터가 많지 않기 때문에 데이터의 편향성을 제거하기 위해 교차검증을 자주 사용한다.
logi_model = LogisticRegression()
rs = cross_val_score(logi_model, X_train, y_train, cv=7) # 교차검증 횟수는 7번display(rs)
display(rs.mean())out :

5. 모델 하이퍼파라미터 튜닝
6. 모델 평가
5,6번은 이따가 진행하고 지금은 7. 모델활용을 먼저 진행하겠습니다.
7. 모델 활용
활용을 할 때 그냥 써도 되지만 사이킷런에서 사용성 좋게 나온 것이 있다.
우리가 지금 사용하고 있는 모델은 :
- CV (CountVectorizer) => 비정형화인 리뷰를 넣어서 정형화를 시킨 후
- LR (LogisticRegression) => 이 모델에 넣어서 부정이라면 0, 긍정이라면 1로 바뀐다.
이 과정을 반드시 거쳐야 하는데, 일단 우리는 어떻게 나오는지 보기 위해 모델 활용을 먼저 해보겠습니다.
# 로튼 토마토 영화리뷰를 가져와서 사용해보도록 하겠습니다.
review = ["Me After seeing Wonder Woman 1: I wish there was a sequel. Me after seeing Wonder Woman 2: I renounce my wish!!! What a waste to time and talent to produce this piece of crap movie. I think Batman & Robin might be better than this movie, that's how bad this movie is. Pedro Pascal is the only shining light in this movie. What a great actor he is. Even the scenes with Gal are rose-colored lenses, over composited and lacking in highlighting her appeal. Dear editor and Patti Jenkins. WTF??? The ending outfit is stupid. The bad guys are stupid. It's like this movie was mixed with a child's cartoon. The opening scenes with WW as a child are pretty good. The ending climatic soliloquy is kinda cool, but the people in the edit are zoomed 20% too close. Editor's work of this movie sucks. So many confusing cuts and obvious special effects. Rotten Movie. Save your $$. Not worth the 2 hours of time. Too bad because the first WW is so good.",
"bad movie from beginning to end, weak script and seems to be done by a teenager in tusks, very bad action scenes, a lot of meaningless and poorly explained",
"This movie is a tribute to comics and to superheroes of the 80's, because the story is told just as if we were in the eighties. and that is why millennials don't get to understand it. No blood at all, not unnecessary violence, just heart, faith, and a wonderful message. It seems that the world can't forgive that this is not another marvel style movie. A few little holes in the story (I have to admit), but such bad opinions seem to be a promoted campaign.",
'5d ago The perfect film for the moment we are living in, a great job by director Patty Jenkins. I loved Barbara Minerva and I hope she will return in the next films.']
# 부정리뷰 2개, 긍정리뷰 2개. 이렇게 가져온 상태.
review_transformed = movie_vect.transform(review)
logi_model.fit(X_train,y_train)out : LogisticRegression()
pre = logi_model.predict(review_transformed)
pre빈도기반으로 예측하기 때문에 리뷰 길이가 길면 길수록 좀 더 잘 맞출 확률이 커진다.
why?
- 토큰이 그만큼 많아진다.
- 긍정과 부정표현 단어들도 그만큼 더 많이 등장한다.
prob = logi_model.predict_proba(review_transformed)
prob
위와 같은 결과가 나왔을 때 읽는 방법. 부동소숫점 표현 방식.
- e+ : 소숫점을 뒤로 이동.
- e- : 소숫점을 앞으로 이동.
- 9.99999872e-01을 해석하면 0.99 = 99%,
- 1.28098313e-07을 해석하면 0.0000001 = 0.00001%
- 지금 우리는 이진분류 방식을 사용하기 때문에 9.99999872e-01는 0번(부정리뷰) 확률, 1.28098313e-07는 1번(긍정리뷰) 확률
파이프라인 구축

리뷰데이터 예측 방법에 사이킷런 말고도 파이프라인이라는 방법도 있다.
각 파이프 별로 나눠서 하는 방식.
from sklearn.pipeline import make_pipeline
movie_pipe = make_pipeline(movie_vect,logi_model)
# 정형화와 예측을 한 세트로 만들어준다# 원더우먼 영화리뷰를 집어넣어 예측해봅시다
movie_pipe.predict(review)out : array([0, 0, 0, 1])
파이프라인은 데이터분석을 하는 일련의 프로세스로 사용의 편의성을 이용해 한큐에 진행될 수 있도록 제작된 방식이다.
편의성도 편의성인데 이게 어떻게 적용될까? 튜닝할 때 도움이 된다. 로지스틱 모델도 튜닝이 가능하지만,
bow를 지원해주는 Count백포라이저?도 튜닝이 가능하다.
규제를 줄 수 있는 c값을 튜닝해줄 수 있다.
지금까지는 모델 하나씩만 튜닝이 가능했다. 하지만 movie_vect,logi_model를 따로 튜닝하면 올바른 방법이라고 할 수 없다.
혼자만 c값을 열심히 찾아봤자 필요가 없다. 앞에서 얼마나 튜닝했는지 movie_vect 상황에 따라 logi_model 튜닝값도 달라져야 하기 때문에 같이 세트로 움직여야 올바른 방식의 튜닝을 진행할 수 있다.
5. 모델 하이퍼파라미터 튜닝
으로 돌아가서 설명을 진행.
-
CountVectorrizer → 정형화 ( 토큰화, 수치화)
- min_df, max_df
- df의 의미 : document frequency. 어떤 하나의 단어가 있으면 전체 문서에서 얼마나 등장하는지 빈도를 확인하는 것이 바로 frequency.
- min_df : 최소 등장 횟수.
- 긍정과 부정을 판가름하기 위해 필요한 빈도 수로, '좋다'라는 단어가 단 한 번 등장하면 의미가 없다. 의미 없는 단어(빈도가 낮은 단어)는 제거를 통해 학습과정에서 머신러닝모델이 가벼워지므로 성능면에서 뛰어나고 실용성도 좋다.
- 등장 숫자는 우리가 직접 설정해줘야 한다. (예 : 3번 이하 제거)
- 오탈자를 제거하는 효과도 가져간다.
- (논외) 긍정과 부정 모두에서 자주 등장하는 단어? : 애매한 단어. 예를 들어 영화리뷰라면 '영화'라는 단어는 자주 등장하게 될 것이다. 이처럼 의미없는 단어도 제외될 필요성이 있다.
- max_df : 등장 최대 제한 횟수.
- 불용어와 연관이 있으면서 약간 다르다.
- 너무 과도하게 전체 문서에서 발생하는 단어는 텍스트마이닝에서 의미가 없다.
- 2만건으로 설정한다? : 2만건 이상 등장하는 단어는 학습에 있어서 도움이 되지 않는다고 판단하여 탈락시킬 수 있다.
- 감성분석에서는 긍정과 부정으로 나뉘지만 sns분석 등에서는 사용하는 방법이 달라질 수 있다.
- n_gram
- 문장을 토큰화해서 단어화시키면 문장 관계성을 다 잃어버리는 BOW.
- 이러한 관계성을 보완하기 위해 나온 것이 바로 n_gram이다.
- 토큰화할 때 단어를 1개씩 묶을지, 2개씩 묶을지 설정해줄 수 있다.
- 유니 : 나는/어제/밥을/먹었다/정말/맛있는/사과
- 바이 : 나는 어제/어제 밥을/밥을 먹었다/정말 맛있는/맛있는 사과
- 트라이 : 나는 어제 밥을/어제 밥을 먹었다/정말 맛있는 사과
- 토큰 방식은 일반적으로 위에 작성된 3가지를 주로 사용하며 각 토큰방식은 섞어서 학습시킬 수 있다.
- 예를 들어 유니와 바이를 섞는다면 단어 사이의 관계를 모델에게 좀 더 학습시킬 수 있을 것이다.
- min_df, max_df
-
LogisticRegression
- C
from sklearn.pipeline import make_pipeline
pipe_model = make_pipeline(CountVectorizer(), LogisticRegression())
from sklearn.model_selection import GridSearchCV# CountVectorizer(), LogisticRegression()가 엮여있으므로
# parameter를 사용할 때도 어디에 들어있는 것을 사용할 것인지 정확히 명시해줘야한다.
param_grid = {
'logisticregression__C':[0.01, 0.1, 1, 10, 100],
# 선형모델의 값을 딱 맞게 규제할 것인지, 조금 널널하게 규제할 것인지 정해준다.
'countvectorizer__max_df':[15000, 20000, 23000], # 최대 등장 횟수
'countvectorizer__min_df':[3, 5, 7], # 최소 등장 횟수
'countvectorizer__ngram_range':[(1,1),(1,2),(1,3)]
# 유니그램, 바이그램 등을 섞어서 쓸 수 있으므로 튜플형태로 기재.
# (1,2) 유니그램부터 바이그램까지 사용하겠다. (2,2)라면 바이그램만 쓰겠다는 의미.)
# (1,3) 유니부터 트라이그램까지 사용하겠다.
}grid = GridSearchCV(pipe_model, param_grid, cv=3)
grid.fit(text_train,y_train)상당히 많은 양의 데이터를 처리하기 때문에 시간이 오래 걸린다.
print(grid.best_score_)
print(grid.best_params_)
'K-디지털 빅데이터 분석서비스 개발자과정 20.11.02~21.04.12 > PYTHON(웹크롤링, 머신·딥러닝)' 카테고리의 다른 글
| 21.02.16. 딥러닝 - XOR논리(다중 퍼셉트론), 딥러닝 프레임워크, tqdm을 활용한 반복수 확인, 학습과정(fit()) 직접 구현 (0) | 2021.02.17 |
|---|---|
| 21.02.15. 딥러닝 - 주피터 노트북 환경설정, 이론(뉴런, 시냅스, …), AND·OR·XOR논리 (0) | 2021.02.15 |
| 21.01.12. 머신러닝 - Decision Tree, Bagging, Random Forest, Boosting (0) | 2021.01.12 |
| 21.01.11. 머신러닝 - lasso, ridge, 선형 분류 모델 (0) | 2021.01.11 |
| 21.01.08. 머신러닝 - 선형모델학습 (0) | 2021.01.08 |



