

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
Tags
- 오블완
- 3000 port kill
- conda base 활성화
- 실행중인 포트 죽이기
- conda 가상환경 설정 오류
- conda base 기본 설정
- 티스토리챌린지
- window netstat time wait 제거
- conda 기초 설정
- 려려
- time wait port kill
Archives
- Today
- Total
모도리는 공부중
21.01.12. 머신러닝 - Decision Tree, Bagging, Random Forest, Boosting 본문
K-디지털 빅데이터 분석서비스 개발자과정 20.11.02~21.04.12/PYTHON(웹크롤링, 머신·딥러닝)
21.01.12. 머신러닝 - Decision Tree, Bagging, Random Forest, Boosting
공부하는 모도리 2021. 1. 12. 14:19728x90
반응형
Decision Tree(결정트리)
- 직관적으로 이해하기 쉬운 알고리즘
- 데이터에 있는 규칙을 학습을 통해 자동으로 찾아냄
- 규칙은 예/아니오 로 대답할 수 있는 질문을 남김
- 매 / 펭귄 / 돌고래 / 곰을 나눠보자
Decision Tree(결정트리) 단점
- 결정트리는 수직적 구조로 인해 중간에 에러가 발생하면 다음 단계로 에러가 계속 전파
- 학습 데이터에 따라 생성되는 결정트리의 구조가 다르기 때문에 일반화하여 사용하기 어렵다.
- 결정트리는 과대적합을 막기 어렵다.
Ensemble(앙상블)
- 앙상블(ensemble)은 여러 머신러닝 모델을 연결하여 더 강력한 모델을 만드는 기법
Decision Tree Ensemble(결정트리 앙상블)
- 개별 결정트리의 과대적합되는 단점을 보완하는 모델
- 다수결 법칙 또는 평균등으로 통합하여 예측 정확성을 향상
- 결정트리 모델들이 서로 독립적
- 결정트리 모델들이 무작위 예측을 수행하는 모델보다 성능이 좋을 경우
- → 서로 독립적인 다양한 모델을 만들자
배깅(Bagging)
- 데이터에 변화시켜서 각각의 데이터를 강화시키는 방식.
- 하나의 데이터를 어떻게 여러 모델에 다양하게 나눠줄 것인지 정하는 Bootstrap
- 각 모델에서 나온 예측값들을 어떻게 모을 것인지 정하는 Aggregating
Bagging(Bootstrap + Aggregating)
- Bootstrap
- 샘플링 기법으로 복원추출 방식을 사용
- 63.2%의 데이터셋을 사용
- 데이터의 수만큼 크기를 갖도록 샘플링
- 다른 데이터셋을 통해 다양한 모델 구축
- 개별 데이터셋을 부트스트랩셋이라고 부름
- 개별 결정트리의 과대적합되는 현상을 막을 수 있음
- 이론적으로 하나의 개체가 하나의 부트스트랩에 한번도 선택되지 않을 확률


- Aggregating
- 평가기법



RandomForest
- 서로 다른 방향으로 과대적합된 트리를 많이 만들고 평균을 내어 일반화시키는 모델
- 배깅의 방법을 디시전트리에 사용한 방법
- 디시전트리의 단점인 과대적합(특정한 데이터 학습을 많이 한 것)을 사용.
- 과대적합한 데이터를 평균을 냄으로써 잘 사용할 수 있도록 일반화시킴.
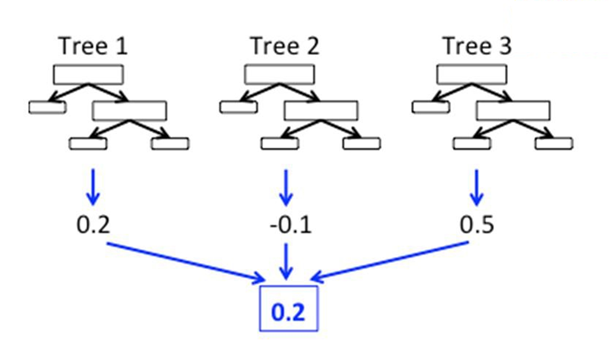
- 장단점 및 주요 매개변수(Hyperparameter)
- 생성 할 트리의 개수 : n_estimators
- n개의 데이터 부트스트랩 샘플 구성
(n개의 데이터 포인트 중 무작위로 n횟수만큼 반복 추출, 중복된 데이터가 들어있을 수 있다.) - 무작위로 선택될 후보 특성의 개수 : max_features
- (각 노드 별로 max_features 개수 만큼 무작위로 특성을 고른 뒤 최선의 특성을 찾는다.)
- 높은 값을 주면 안된다.
- max_features를 높이면 트리들이 비슷해진다.
- 결정트리의 단점을 보완하고 장점은 그대로 가지고 있는 모델이어서 별다른 조정 없이도 괜찮을 결과를 만들어낸다.
- 트리가 여러 개 만들어지기 때문에 비전문가에게 예측과정을 보여주기는 어렵다.
- 랜덤하게 만들어지기 때문에 random_state를 고정해야 같은 결과를 볼 수 있다.
- 텍스트 데이터와 같은 희소한 데이터에는 잘 동작하지 않는다.
- 큰 데이터 세트에도 잘 동작하지만 훈련과 예측이 상대적으로 느리다.
- 트리 개수가 많아질 수록 시간이 더 오래 걸린다.
부스팅(Boosting)
- 모델들이 서로 연결되어 있음.
- 조금씩만 맞히고 다음 단계로 넘어감으로써 각각의 모델 강화시켜 결과적으로 많은 값을 맞힐 수 있도록 하는 방식.
GradientBoosting
- 정확도가 낮더라도 얕은 깊이의 모델을 만든 뒤, 나타난 예측 오류를 두 번째 모델이 보완한다.
- 이전 트리의 예측 오류를 보완하여 다음 트리를 만드는 작업을 반복한다.
- 마지막까지 성능을 쥐어짜고 싶은 경우 사용한다, 주로 경진 대회에서 많이 활용.
(GradientBoosting을 더 발전시킨 XGBoost도 있음) - 장단점 및 주요 매개변수(Hyperparameter)
- 보통 트리의 깊이를 깊게하지 않기 때문에 예측 속도는 비교적 빠르다. 하지만 이전 트리의 오차를 반영해서 새로운 트리를 만들기 때문에 학습속도가 느리다.
- 특성의 스케일을 조정하지 않아도 영역을 나누는 방식으로 진행되기 때문에 괜찮다.
- 희소한 고차원 데이터에는 잘 동작하지 않는다.
- 생성 할 트리의 개수 : n_estimators
(트리가 많아질 수록 과대적합이 될 수 있다.) - 오차를 보정하는 정도 : learning_rate
(값이 높을 수록 오차를 많이 보정하려고 한다. ) - 트리의 깊이 : max_depth
(일반적으로 트리의 깊이를 깊게 설정하지 않는다.)
Grid Search
- 하이퍼파라미터를 여러 개 조정하여 모델을 만들 경우 사용하는 방법 (하이퍼파라미터 튜닝)
타이타닉학습 파이썬을 실행하여 이어서 작성해보도록 합시다.
Ensemble
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier
forest_model = RandomForestClassifier()
gradient_model = GradientBoostingClassifier()
# forest 특성
# max_depth
# n_estimators
# max_features
# max_leaf_modes
forest_model.fit(X_train,y_train)
print(forest_model.score(X_train,y_train))
print(forest_model.score(X_val,y_val))out :
0.9940119760479041
0.7982062780269058
forest_model2 = RandomForestClassifier(n_estimators = 1000,
max_features = 0.7,
max_depth = 5,
max_leaf_nodes = 50)
grid = GridSearchCV(forest_model2, param_grid, cv=3)
grid.fit(X_train,y_train)
print('best score : ',grid.best_score_)
print('best params : ',grid.best_params_)out :
best score : 0.844301700803943
best params : {'max_depth': 15, 'max_features': 0.7, 'max_leaf_nodes': 50, 'n_estimators': 1000}
728x90
반응형
'K-디지털 빅데이터 분석서비스 개발자과정 20.11.02~21.04.12 > PYTHON(웹크롤링, 머신·딥러닝)' 카테고리의 다른 글
| 21.02.15. 딥러닝 - 주피터 노트북 환경설정, 이론(뉴런, 시냅스, …), AND·OR·XOR논리 (0) | 2021.02.15 |
|---|---|
| 21.01.14. 머신러닝 - 텍스트마이닝 두 번째 시간 (0) | 2021.01.14 |
| 21.01.11. 머신러닝 - lasso, ridge, 선형 분류 모델 (0) | 2021.01.11 |
| 21.01.08. 머신러닝 - 선형모델학습 (0) | 2021.01.08 |
| 21.01.07. 머신러닝 개념복습, 데이터스케일링, 선형모델 (0) | 2021.01.07 |
'K-디지털 빅데이터 분석서비스 개발자과정 20.11.02~21.04.12/PYTHON(웹크롤링, 머신·딥러닝)' Related Articles
more




Comments