
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 오블완
- conda base 기본 설정
- conda 기초 설정
- 3000 port kill
- time wait port kill
- window netstat time wait 제거
- 티스토리챌린지
- conda 가상환경 설정 오류
- 려려
- conda base 활성화
- 실행중인 포트 죽이기
- Today
- Total
모도리는 공부중
21.01.11. 머신러닝 - lasso, ridge, 선형 분류 모델 본문
21.01.11. 머신러닝 - lasso, ridge, 선형 분류 모델
공부하는 모도리 2021. 1. 11. 12:59어제 수업에 이어서 -
| 규제 강화 (alpha) | |
| Lasso | 일부특성 사용x |
| Ridge | 모든특성 사용 |
이러한 이유로 모든 특성을 사용하는 Ridge모델이 일반적으로 점수를 더 잘 내는 특징을 가지고 있다.
# alpha = 1
ridge = Ridge(alpha = 1)
ridge.fit(extend_X_train, y_train)
print('train score : ',ridge.score(extend_X_train,y_train))
print('test score : ',ridge.score(extend_X_test,y_test))
# 사용한 특성의 개수
print('사용한 특성의 개수 : ',np.sum(ridge.coef_!=0))out :
train score : 0.9187927699238897
test score : 0.9121389207829017
사용한 특성의 개수 : 182
→ 규제를 1로 준 것이 가장 일반화가 잘된 상태임을 알 수 있다.
# alpha = 100
ridge = Ridge(alpha = 100)
ridge.fit(extend_X_train, y_train)
print('train score : ',ridge.score(extend_X_train,y_train))
print('test score : ',ridge.score(extend_X_test,y_test))
# 사용한 특성의 개수
print('사용한 특성의 개수 : ',np.sum(ridge.coef_!=0))out :
train score : 0.8980910657371644
test score : 0.9046632523652257 ← 찍은 것 중에 맞힌게 더 많은 상황. 과소적합.
사용한 특성의 개수 : 182
# alpha = 0.001
ridge = Ridge(alpha = 0.001)
ridge.fit(extend_X_train, y_train)
print('train score : ',ridge.score(extend_X_train,y_train))
print('test score : ',ridge.score(extend_X_test,y_test))
# 사용한 특성의 개수
print('사용한 특성의 개수 : ',np.sum(ridge.coef_!=0))out :
train score : 0.9280749930098602
test score : 0.8959170601911298
사용한 특성의 개수 : 182
→ train에 너무 많은 학습을 시켜 과대적합 발생

선형 분류 모델
분류용 선형 모델
- y = 𝒘𝟏𝒙𝟏 + 𝒘𝟐𝒙𝟐 + 𝒘𝟑𝒙𝟑 + ⋯ + 𝒘𝒑𝒙𝒑 + 𝒃 > 𝟎
- 특성들의 가중치 합이 0보다 크면 class를 +1 (양성클래스)
- 0보다 작다면 클래스를 -1 (음성클래스)로 분류한다.
- 분류용 선형모델은 결정 경계가 입력의 선형함수
- 일대다 방법을 통해 다중 클래스 분류


Logistic Regression (분류모델)
- 회귀공식을 사용해서 Regression이라는 이름이 붙음
- 결정 경계가 선형이기 때문에 선형 모델
- 새로운 관측치가 왔을 때 기존 범주중 하나로 예측할 때 사용
- 시그모이드 함수의 최적선을 찾고 반환값을 확률로 간주
- 비용함수로 시그모이드 함수 채택
- 선형 함수의 결과 값을 Sigmoid Function(Logistic Function)을 이용해 0과 1로 변환한다.


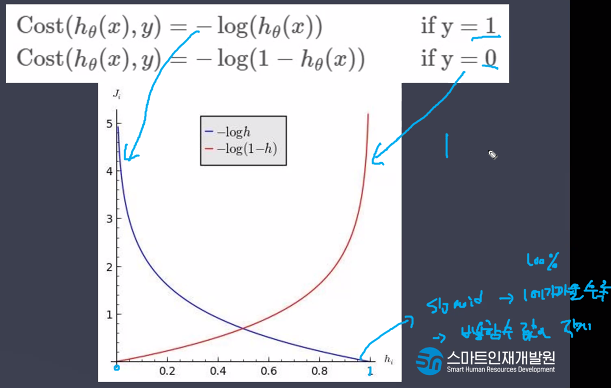
주요 매개변수(Hyperparameter)
- 선형 분류 모델 : C (값이 클수록 규제가 약해진다.)
- 기본적으로 L2규제를 사용, 하지만 중요한 특성이 몇 개 없다면 L1규제를 사용해도 무방 (주요 특성을 알고 싶을 때 L1 규제를 사용하기도 한다.)

규제가 강해지면 특성이 작아지고 ( c = 0.010000 )
규제가 약해지면 특성이 많아진다 ( c = 1000.000000 )
Support Vector Machine (SVM)


- 회귀 선형 모델 : alpha (값이 클수록 규제가 강해진다.)
- 선형 분류 모델 : C (값이 클수록 규제가 약해진다.)
- 기본적으로 L2규제를 사용, 하지만 중요한 특성이 몇 개 없다면 L1규제를 사용해도 무방. (주요 특성을 알고 싶을 때 L1 규제를 사용하기도 한다.)
- 선형 모델은 학습 속도가 빠르고 예측도 빠르다.
- 매우 큰 데이터 세트와 희소 (sparse)한 데이터 세트에서도 잘 동작한다.
- 특성이 많을 수록 더욱 잘 동작한다.
- 저차원(특성이 적은)데이터에서는 다른 모델이 더 좋은 경우가 많다.
독버섯 데이터 분류 실습
import pandas as pddata = pd.read_csv('mushroom.csv')
data.head()

버섯의 특징을 활용해 독 / 식용 버섯을 분류
# 결측치 확인
data.info()
# 학습용 데이터이기 때문에 결측치는 x.
# 하지만 바로 사용할 수 없음. why? - Dtype
# type이 object로, 전체 다 수치형이 아닐 가능성이 높음.
# 원핫 인코딩을 통해 수치화 필요.
데이터 셋 분리
X = data.drop('poisonous',axis=1)
y = data['poisonous']from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X,y,
random_state=3,
test_size=0.3)# 원핫인코딩
X_train_onehot = pd.get_dummies(X_train)
X_test_onehot = pd.get_dummies(X_test)X_train_onehot.shape,X_test_onehot.shapeout : ((5686, 117), (2438, 116))
train과 test를 봐서 없는 컬럼 찾기
# train에는 있고 test에는 없는 컬럼
set(X_train_onehot) - set(X_test_onehot)out : {'cap-shape_c'}
# test에는 있고 train에는 없는 컬럼
set(X_test_onehot)-set(X_train_onehot)out : set()
# 없는 컬럼 생성
# 어차피 없는 값이기 때문에 0으로 값을 채워도 무방.
X_test_onehot['cap-shape_c'] = 0# 특성의 순서 맞추기
# sort_index()
X_train_onehot = X_train_onehot.sort_index(axis=1)
X_test_onehot = X_test_onehot.sort_index(axis=1)모델링
from sklearn.linear_model import LogisticRegression
from sklearn.svm import LinearSVC #linear support vector machine에서 분류모델을 가져온 것.
logi_model = LogisticRegression()
svc_model = LinearSVC()
분류 평가 지표
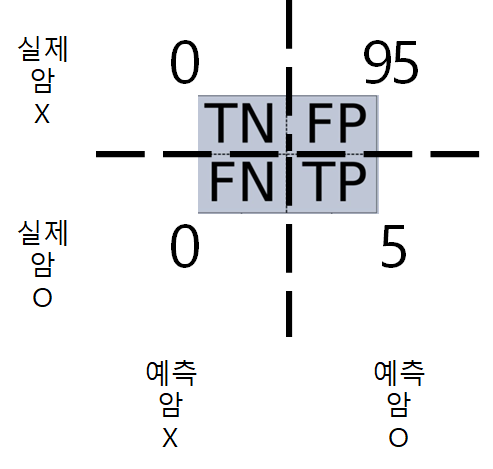
Confusion_matrix
N과 P는 예측, T는 True, F는 False.
- 정확도(Accuracy) : 전체 중에 정확히 맞힌 비율






- 재현율(Recall) : 실제 양성 중에 예측 양성 비율





- 정밀도(Precision) : 예측 양성 중에 실제 양성 비율



- F1 - score : 정밀도와 재현율의 조화평균

- 낮은 재현율보다 높은 정밀도를 선호하는 경우 - 실제 N을 P라고 판단하면 안되는 경우
- 어린아이에게 안전한 동영상(양성)을 걸러내는 분류기를 훈련시킬 경우 좋은 동영상이 많이 제외되더라도(낮은 재현율) 안전한 것들만 노출시키는(높은 정밀도) 분류기가 더 좋다.
- 낮은 정밀도보다 높은 재현율을 선호하는 경우 - 실제 P를 N이라고 판단하면 안되는 경우
- 감시 카메라로 좀도둑(양성)을 잡아내는 분류기를 훈련시킬 경우 경비원이 잘못된 호출을 종종 받지만(낮은 정밀도) 거의 모든 좀도둑을 잡는(높은 재현율) 분류기가 더 좋다.
ROC curve


최적의 규제값(C) 찾기
logi_model = LogisticRegression(C = 10)
logi_model.fit(X_train_onehot,y_train)
print(logi_model.score(X_train_onehot,y_train))
print(logi_model.score(X_test_onehot,y_test))out :

svc_model = LinearSVC(C = 0.1)
svc_model.fit(X_train_onehot,y_train)
print(svc_model.score(X_train_onehot,y_train))
print(svc_model.score(X_test_onehot,y_test))out : 1.0 1.0
from sklearn import metrics
# 예측값
# predict
pre = svc_model.predict(X_test_onehot)
print(metrics.classification_report(pre,y_test))
# micro avg : 정답에 대해 빈도로 평균 구함(micro와 macro 같을 경우 안 나오는 경우도 있음)
# macro avg : 정답에 대해 비율로 평균 구함out :

'K-디지털 빅데이터 분석서비스 개발자과정 20.11.02~21.04.12 > PYTHON(웹크롤링, 머신·딥러닝)' 카테고리의 다른 글
| 21.01.14. 머신러닝 - 텍스트마이닝 두 번째 시간 (0) | 2021.01.14 |
|---|---|
| 21.01.12. 머신러닝 - Decision Tree, Bagging, Random Forest, Boosting (0) | 2021.01.12 |
| 21.01.08. 머신러닝 - 선형모델학습 (0) | 2021.01.08 |
| 21.01.07. 머신러닝 개념복습, 데이터스케일링, 선형모델 (0) | 2021.01.07 |
| 20.12.31. 머신 러닝 (0) | 2020.12.31 |



