
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 오블완
- conda base 활성화
- 3000 port kill
- conda 가상환경 설정 오류
- 티스토리챌린지
- 려려
- conda base 기본 설정
- conda 기초 설정
- time wait port kill
- 실행중인 포트 죽이기
- window netstat time wait 제거
- Today
- Total
모도리는 공부중
21.01.07. 머신러닝 개념복습, 데이터스케일링, 선형모델 본문
21.01.07. 머신러닝 개념복습, 데이터스케일링, 선형모델
공부하는 모도리 2021. 1. 7. 16:16머신러닝 개념 복습
머신러닝 ??
- 데이터를 이용하여 특성과 패턴을 학습하고 그 결과를 바탕으로 새로운 데이터에 대해 결과를 예측하는 것
통계 기반 데이터 분석(기존) vs 머신 러닝 기반 데이터 분석(현재)
- 통계 기반 : 분석하는 사람의 지식에 따라 결과가 크게 달라질 수 있다.
- 머신러닝 기반 : 사람 + 머신러닝 (상대적으로 사람의 능력이 떨어져도 분석이 가능)
머신러닝 방법
- 지도학습 : 문제와 답(label)을 함께 보여주고 학습하는 방법
- 회귀 : 정답 데이터가 수치형 데이터 (ex. 키, 몸무게, 부동산가격)
- 분류 : 정답 데이터가 범주형 데이터 (ex. 등급, 학점(ABCD))
- 비지도학습 : 답이 없는 데이터를 가지고 패턴을 찾고 싶을 때 사용하는 방법
- 군집 : 비슷한 데이터를 묶어서 그룹별 패턴을 해석하는 방법
- 강화학습 : 보상을 주는 개념으로 학습하는 방법(완벽한 답을 주지는 않는다.) (ex. 게임점수 획득방식)
머신러닝 프로세스
- 문제정의
- 탑승객의 정보를 바탕으로 생존자 / 사망자 판단
- 데이터 수집
- kaggle 사이트로부터 수집
- 데이터 전처리 : 결측치 제거 및 추가정보를 위한 새로운 데이터 생성 등
- 컬럼 삭제
- PassingerId 삭제 : 승객의 번호로 생존자 / 사망자 예측이 불가능하기 때문.
- Embarked : 최빈값으로 결측치 채움
- Fare : 대개 중앙값이나 평균값을 사용. 우리는 중앙값을 사용(평균값에는 이상치가 많아 사용하기에 부적합).
- Age : 특성간의 상관관계를 통해서 채움(Pclass, Sex). 이것 역시 중앙값을 이용하여 결측치 채움.
- Cabin : 결측치를 하나의 데이터로 활용하기 위해 결측치에 특정한 값 부여.
- Family_Size : 컬럼 생성(형제자매수+부모자식수+본인). 비슷한 특성끼리 묶어서 범주화.
- Title2 : 'Name'컬럼 중간에 있는 호칭만 따로 뽑아서 사용(Mr, Miss, …)
- 사용하지 않을 컬럼 삭제(Name, Ticket, Title)
- 원핫 인코딩 : 글자데이터 → 숫자데이터로 인코딩
- 사용하는 이유 : 머신러닝 모델은 글자데이터를 학습하지 못하기 때문.
- 타이타닉데이터는 범주형이 아닌 숫자형데이터.
- 원핫 인코딩에 사용된 컬럼 삭제
- 탐색적 데이터 분석(EDA, 데이터 시각화)
- 데이터의 특성을 이해
- 모델링 : 모델 선택 및 하이퍼 파라미터 튜닝
- KNeighborsClassifier(n_neighbors = 1 ~ 150) 9
- DecisionTreeClassifier(max_depth = 1 ~ 150) 5
- 모델학습
- train_test_split
- 훈련용 데이터 (70 ~ 75%)
- 평가용 데이터 (25 ~ 30%)
- 학습을 더 유도하려면 훈련 데이터 비율을 증가
- 평가의 신뢰도를 높이고 싶을 땐 평가 데이터의 바율을 증가
- 모델 평가
- 분류(맞힌 개수 기반) : 정화도, 재현율, 정밀도, f-1 score, ROC curve
- 회귀(오차 기반) : MSE, RMSE, MAPE, R2, …
- 모델 서비스화
일반화, 과대적합, 과소적합
- 과소적합 : 훈련데이터에서 충분한 학습을 하지 못해 훈련데이터에서도 성능이 안 좋고, 평가데이터에서도 성능이 안 좋은 경우
- 과대적합 : 훈련데이터에서 너무 많은 학습을 진행해서 훈련데이터만 잘 맞추고 테스트데이터는 못 맞히는 경우
- 일반화 : 훈련데이터에서 적당한 학습을 진행해서 테스트 데이터에 대해 잘 맞히는 경우
모델의 일반화를 유도하는 방법
- 데이터 : 데이터의 양을 늘린다.
- 편중된 데이터만 늘리는 것은 도움이 되지 않는다.
- 모델 : 모델의 복잡도를 제어(하이퍼 파라미터 튜닝).
교차검증
- 데이터 전체에 과대적합이 걸리는 것을 방지
- 일반화가 잘된 모델을 찾기 위함
- train(훈련), validation(검증), test(평가)
- 훈련데이터와 검증데이터를 통해 일반화가 잘된 모델을 찾음
- 평가데이터로는 일반화가 잘된 모델을 평가
- 평가데이터에 과대적합이 걸릴 가능성을 제거
- k-fold cross validation (k-겹 교차검증)
- val 세트가 존재하지 않음
- 데이터를 바꿔가면서 학습하는 과정으로 val을 대체
- 데이터를 k개로 나눔
- 각 데이터가 한 번씩 test데이터가 되도록 학습을 k번 진행
- k번의 결과를 평균낸 값을 사용
데이터 스케일링 (Data scaling)
- 특성(Feature)들의 범위(range)를 정규화 해주는 작업
- 특성마다 다른 범위를 가지는 경우 머신러닝 모델들이 제대로 학습되지 않을 가능성이 있다. (KNN, SVM, Neural network 모델, Clustering 모델 등)

장점
- 특성들을 비교 분석하기 쉽게 만들어 준다.
- Linear Model, Neural network Model 등에서 학습의 안정성과 속도를 개선시킨다.
- 하지만 특성에 따라 원래 범위를 유지하는게 좋을 경우는 scaling을 하지 않아도 된다.
종류 (교재 178쪽 하단 참고)

▶ StandardScaler
- 전체 데이터를 사용
- 변수의 평균,표준편차를 이용해 정규분포 형태로 변환 (평균 0, 분산 1)
- 이상치(Outlier)에 민감하게 영향을 받는다.
▶ RobustScaler
- 변수의 사분위수를 이용해 변환 (전체 데이터를 사용하지 않음)
- 이상치(Outlier)가 있는 데이터 변환시 사용할 수 있다.
▶ MinMaxScaler
- 전체 데이터를 사용
- 변수의 Max 값, Min 값을 이용해 변환 (0 ~ 1 사이 값으로 변환)
- 이상치(Outlier)에 민감하게 영향을 받는다.
▶ Normalizer
- 특성 벡터의 길이가 1이 되도록 조정 (행마다 정규화 진행)
- 특성 벡터의 길이는 상관 없고 데이터의 방향(각도)만 중요할 때 사용.
- 텍스트데이터의 유사도를 판단할 때 사용.
Machine Learning시 주의점
- 훈련세트와 테스트세트에 같은 변환을 적용해야 한다. (같은 범위를 가지도록 하기 위함)
- 예를 들어 MinMaxScaler의 경우 훈련세트의 평균과 표준편차를 이용해 훈련세트를 변환하고, 테스트세트의 평균과 표준편차를 이용해 테스트세트를 변환하면 잘못된 결과가 나온다.

Titanic 데이터를 학습한 KNN 모델에 scaler를 적용하여 결과 확인
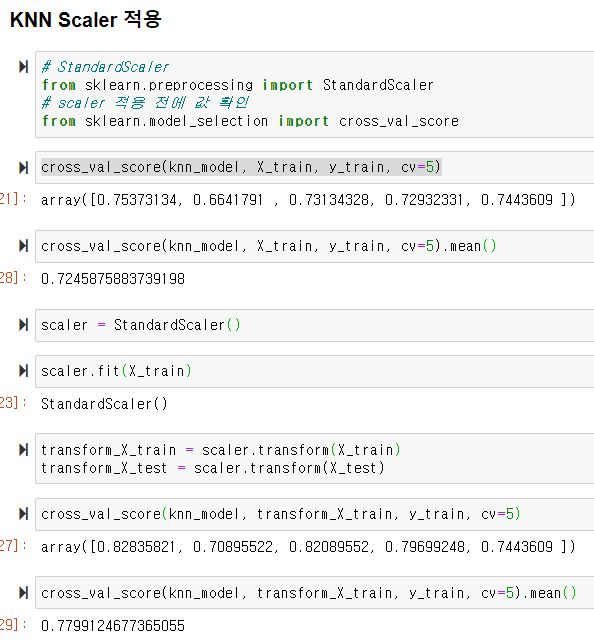
Linear Model ( Regression ) - 선형 모델
- 입력 특성에 대한 선형 함수를 만들어 예측을 수행
- 다양한 선형 모델이 존재한다.
- 분류와 회귀에 모두 사용 가능
| x(hour) | y(score) |
| 9 | 90 |
| 8 | 80 |
| 4 | 40 |
| 2 | 20 |
7시간 공부할 경우 성적은 몇 점이 될까?
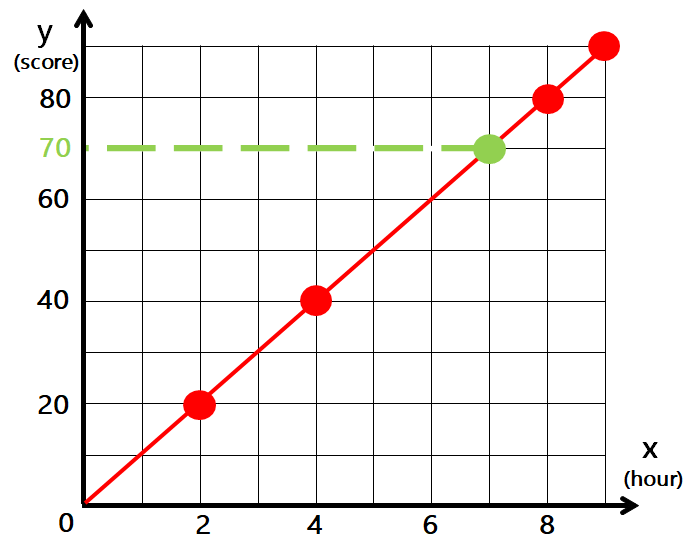

기울기는 가중치, 절편은 절편이라고 부른다.
이런식으로 된다는 것을 알기 위한 식.

- w : 가중치(weight), 계수(coefficient)
- b : 절편(intercept), 편향(bias)
- 모델 w 파라미터 : model.coef_
- 모델 b 파라미터 : model.intercept_
평균제곱오차

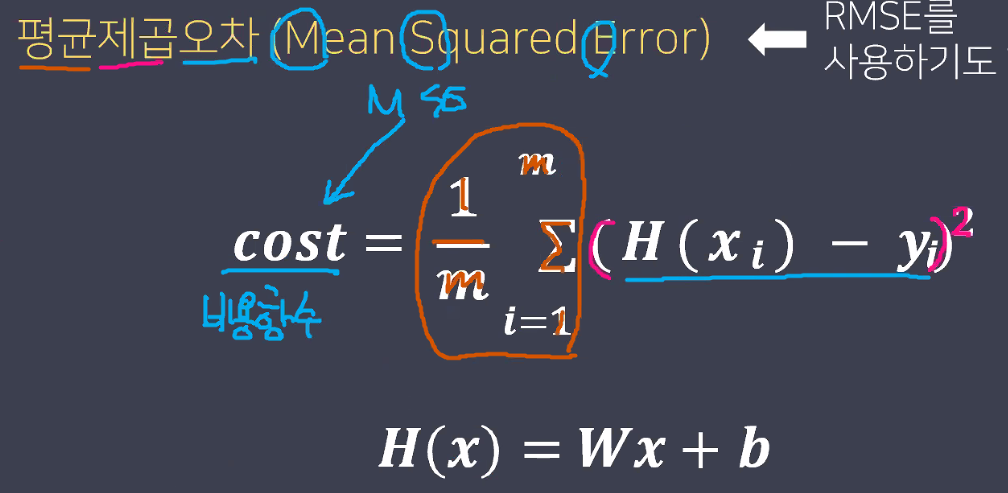
평균제곱오차가 가장 작았을 때 선형함수를 예측값으로 활용.
cost : 비용함수

평균제곱오차(MSE)가 최소가 되는 w와 b를 찾는 방법
1. 수학 공식을 이용한 해석적 방법 (Ordinary Least Squares)
2. 경사하강법 (Gradient Descent Algorithm)
이렇게 있지만 우리는 1번의 방법은 사용하지 않을 것이다. 2번인 경사하강법을 이용할 것.
지금까지 배운 것을 수학공식을 제외하고 최대한 쉽게 다시 이해해보자.
선형모델
- 선형함수를 만들어서 예측을 수행. (선형함수 - 여러개의 특성을 고려)
- ☞ 모든 특성에 정확히 맞는 선형함수는 존재하지 않는다.
- 그래도 최대한 모든 특성을 고려한 선형함수를 찾아야한다.
- 평균 제곱오차가 최소가 될 때(=최대한 모든 특성을 고려)의 w와 b를 선형함수로 사용
- 비용 함수 : 수식을 검증하는 모든 함수
- 평균 제곱 오차 (선형함수의 비용함수)
- 1/데이터수∑(실제 값 - 예측 값)²
- 평균 제곱근 오차 = √평균제곱오차 = RMSE
- 평균 제곱 오차의 값이 매우 커질 때를 대비해서 사용하는 함수.
- 수학적 공식을 이용한 해석적 방법, 경사하강법
- 비용 함수 : 수식을 검증하는 모든 함수
- 평균 제곱오차가 최소가 될 때(=최대한 모든 특성을 고려)의 w와 b를 선형함수로 사용
Linear Regresion (선형 회귀 모델)
- 수학 공식을 이용한 해석적 방법 → 비용함수(평균제곱오차)가 최소가 되는 w, b를 찾음
- w, b 사용해서 선형함수 만들기 → 선형 함수를 선형 모델에 적용시킴 → 예측 값으로 활용
주피터 노트북을 실행시켜서 코드를 입력하며 실습해보자.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
사용할 라이브러리 import
- DataFrame의 형태로 성적 데이터 만들기
- 시간, 성적
- index는 따로 지정하지 않음
data = pd.DataFrame([[9,90],[8,80],[4,40],[2,20]], columns=['시간','성적']) #방법1
data = pd.DataFrame({'시간':[9,8,4,2],'성적':[90,80,40,20]}) #방법2
data
Linear Regression
- 수학 공식을 이용한 해석적 모델
from sklearn.linear_model import LinearRegression
linear_model = LinearRegression()
# 시간 = X(문제)
# 성적 = y(정답)
# 문제는 2차원으로 넣어줘야 한다. (2차원 표현을 위해 대괄호를 2개 씌워준다.)
linear_model.fit(data[['시간']],data['성적'])- 학습이 잘됐다는 LinearRegression() 를 결과로 출력
# 가중치
print(linear_model.coef_)
# 절편
print(linear_model.intercept_)- 결과 :
[10.]
-7.105427357601002e-15
오늘은 여기까지! 수고하셨습니다.
'K-디지털 빅데이터 분석서비스 개발자과정 20.11.02~21.04.12 > PYTHON(웹크롤링, 머신·딥러닝)' 카테고리의 다른 글
| 21.01.11. 머신러닝 - lasso, ridge, 선형 분류 모델 (0) | 2021.01.11 |
|---|---|
| 21.01.08. 머신러닝 - 선형모델학습 (0) | 2021.01.08 |
| 20.12.31. 머신 러닝 (0) | 2020.12.31 |
| 20.11.27.오후 - 웹크롤링 마지막시간 (0) | 2020.11.27 |
| 20.11.23. 오후 - 웹크롤링 이론 및 게임 (0) | 2020.11.23 |



