
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 티스토리챌린지
- 3000 port kill
- conda 가상환경 설정 오류
- time wait port kill
- 려려
- window netstat time wait 제거
- conda base 기본 설정
- conda 기초 설정
- 실행중인 포트 죽이기
- conda base 활성화
- 오블완
- Today
- Total
모도리는 공부중
21.02.16. 딥러닝 - XOR논리(다중 퍼셉트론), 딥러닝 프레임워크, tqdm을 활용한 반복수 확인, 학습과정(fit()) 직접 구현 본문
21.02.16. 딥러닝 - XOR논리(다중 퍼셉트론), 딥러닝 프레임워크, tqdm을 활용한 반복수 확인, 학습과정(fit()) 직접 구현
공부하는 모도리 2021. 2. 17. 14:01저번시간 실습으로 했던 XOR논리 학습에 대한 수업 이어서 갑니다.
X_xor = [[0,0],[0,1],[1,0],[1,1]]
y_xor = [0,1,1,0]# 신경망 설계
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Activaion
model3 = Sequential()
model3.add(Dense(units=1, input_dim=2))
model3.add(Activation("sigmoid"))
model3.summary()out :

# 컴파일
model3.compile(loss="binary_crossentropy", optimizer="adam", metrics=["accuracy"])
# 학습
model3.fit(x=X_xor, y=y_xor, epochs=500000, batch_size=4)어제 돌렸던 50만번... 몇번을 돌리던 75% 이상으로는 학습되지 않는 것을 확인할 수 있다. 오히려 나는 과대적합이 걸려서 50%로 하강하고 그 이후로는 상승하지 않았다.

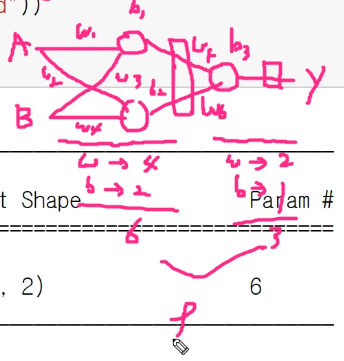
첫 번째 그림은 뉴런이 2개인 경우이고 아래 그림은 뉴런이 3개인 경우이다. 우선은 뉴런이 2개인 경우로 실습을 해보도록 한다.
뉴런을 2개로 늘려서 설계해보자
model4 = Sequential()
model4.add(Dense(units=1, input_dim=2))
model4.add(Activation("sigmoid"))
model4.add(Dense(units=1))
model4.add(Activation("sigmoid"))
model4.summary()out :

파라미터가 5개인 이유? 첫 번째 뉴런에 파라미터가 2개, 두 번째 뉴런에 파라미터가 3개. 이렇게 총 5개.

model4.compile(loss="binary_crossentropy", optimizer="adam", metrics=["acc"])
model4.fit(x=X_xor, y=y_xor, epochs=2000, batch_size=4)out :

7500에서 더 올라가지 않으므로 unit을 2개로 늘려본다. 입력이 2개이므로 출력도 2개로 해서 나온다(?)
model4 = Sequential()
model4.add(Dense(units=2, input_dim=2))
model4.add(Activation("sigmoid"))
model4.add(Dense(units=1))
model4.add(Activation("sigmoid"))
model4.summary()out :

위의 코드에 대한 설명
다시 컴파일하고 fit해본다. 2번 정도 돌려주었더니 1이 나오는 것을 볼 수 있다.

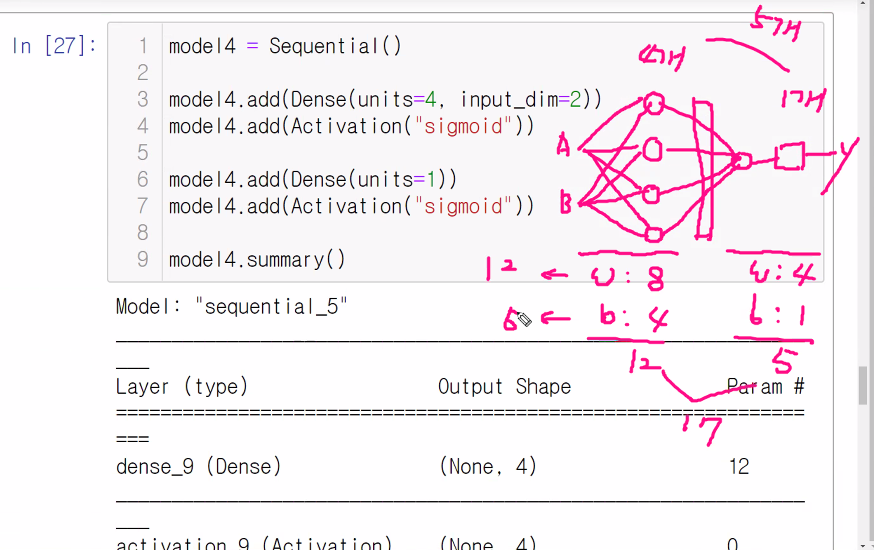
선생님은 1이 나오지 않아서 unit을 4개로 늘려주었다.
신경망이 하는 대표적인 역할은 특성을 추출하는 역할이다. 이렇다보니 신경망의 다른 명칭을 특성추출기라고 부른다. 오차가 가장 적은 최적의 특성을 뽑아내는 역할을 한다. 머신러닝을 할 때 특성을 많이 늘리면 과대적합이 발생한다. 사람은 사람의 얼굴을 보고 특성을 뽑을 때 많아봐야 10가지 정도만 뽑을 수 있다면 컴퓨터가 직접 특성을 뽑으면 무궁무진하게(100개 이상도?) 뽑을 수 있기 때문에 딥러닝은 그만큼 세분화할 수 있다고 생각..
relu는 1을 곱해주는 역할....?
크롤링할 때 사용했던 tqdm. 딥러닝에도 유용하게 사용이 가능하다고 한다.
Tip. 반복수가 증가하면 언제 끝날지 확인해보자
-> tqdm 라이브러리
먼저, 딥러닝용으로 환경설정한 노트북에는 tqdm이 설치되어 있지 않으므로 설치 먼저 해준다.
!pip install tqdm
from tqdm.notebook import tqdm이후 for문을 사용하여 tqdm을 사용하는 fit코드 작성.
for i in tqdm(range(2000)):
model4.fit(x=X_xor, y=y_xor, epochs=1, batch_size=4)for문을 사용하면 epochs를 1로 두어도 for문에서 준 갯수만큼 반복되므로 epochs를 2000번 준 것과 동일한 효과를 누리면서 진행도를 눈으로 직접 확인할 수 있기 때문에 epochs를 많이 줬을수록 사용성에 있어 편리하다.

다층 퍼셉트론 (MLP : Multi Layer Perceptron)
- 사람은 대상이 무엇인지 판단하는 정보들의 경계를 느슨하게 가지고 있음 → 정확하지 않음 → 추상적
- 각 신경 세포 뉴런 은 정보에 대한 각기 다른 기준 을 가지고 있음
- 다층 신경망을 거치면서 정보를 판단하게 됨

- 다른 관점을 가진 전문가를 활용한 판단

모든 내용을 비전문가들이 다 판단하도록 하는게 나을까요, 아니면 전문가들에게 중요내용을 판단하게 한 다음에 나머지를 다수결로 하는게 나을까요?
- 하나의 입력에 대해 뉴런들은 다른 판단을 하고 다음 층으로 전달

입력은 1로 들어왔지만 이 퍼셉트론은 1을 0.6으로 판단하고 있다. 하지만 1이 나오도록 우리는 유도해야 한다.

딥러닝 학습을 직접 한 번 해보도록 합시다.
AND 논리를 구현하는 파라미터 값을 설정하는 연습을 해보자
def ANDGate(x1, x2):
w1, w2, b = ?, ?, ?
y = x1 * w1 + x2 * w2 + b
if y <= 0 :
return 0
elif y > 0 :
return 1
print(ANDGate(0,0)) # 0
print(ANDGate(0,1)) # 0
print(ANDGate(1,0)) # 0
print(ANDGate(1,1)) # 1여기에서 ? 자리에 숫자를 채워서 사용할 수 있다.
이 파트에 대한 상세 설명은 16일 딥러닝 녹화 6교시 파일을 참고하도록 한다. (ㅋㅋㅋㅋㅋㅋㅋㅋㅋ)
일단 수업을 이어가기 위해 해당 코드가 필요하니 여기에 복붙. (수학적인 부분이라서 나도 이해를 못했다..)
# AND Gate
def ANDGate(x1, x2):
w1, w2, b = 1,1,-1
y = x1 * w1 + x2 * w2 + b # 선형회귀 공식
if y <= 0 :
return 0
elif y > 0 :
return 1
print(ANDGate(0,0)) # 0
print(ANDGate(0,1)) # 0
print(ANDGate(1,0)) # 0
print(ANDGate(1,1)) # 1
# NAND Gate
def NANDGate(x1, x2):
w1, w2, b = -0.5,-0.5,0.7
y = x1 * w1 + x2 * w2 + b
if y <= 0 :
return 0
elif y > 0 :
return 1
print(NANDGate(0,0)) # 1
print(NANDGate(0,1)) # 1
print(NANDGate(1,0)) # 1
print(NANDGate(1,1)) # 0
# OR Gate
def ORGate(x1, x2):
w1, w2, b = 0.8, 0.8, -0.1
y = x1 * w1 + x2 * w2 + b
if y <= 0 :
return 0
elif y > 0 :
return 1
print(ORGate(0,0)) # 0
print(ORGate(0,1)) # 1
print(ORGate(1,0)) # 1
print(ORGate(1,1)) # 1
# 그냥 XOR Gate는 시도하면 나오지 않는다.
# 앞서 만든 NAND, OR, AND Gate를 이용하면 우리가 필요한 XOR Gate를 만들어낼 수 있다.
def XORGate(x1, x2):
s1 = NANDGate(x1, x2)
s2 = ORGate(x1, x2)
y = ANDGate(s1, s2)
return y
print(XORGate(0,0)) # 0
print(XORGate(0,1)) # 1
print(XORGate(1,0)) # 1
print(XORGate(1,1)) # 0


기존의 Rule-based expert system은 사람이 직접 데이터를 입력하고 직접 공통적인 연관관계를 정하고 만들어내는 규칙을 통해 찾기 때문에 시간이 오래 걸린다는 단점이 있다. 파라미터가 늘어나면 늘어날수록 복잡한 것이면 사람이 찾기가 어렵다. 그래서 나온 것이 바로 머신러닝이다. 머신러닝은 사람이 라벨데이터와 특성데이터를 선택해서 넣으면 그것을 기반으로 찾아준다. 머신러닝은 SVM이나 KNN을 통해 찾는데 사람은 이 때 깔끔하게 정리하고 가공해서 넣어주기만 하면 되기 때문에 가공된 데이터를 이용하여 편리하게 찾아낼 수 있다.
하지만 사람이 정한 특성 내에서만 머신러닝하기 때문에 한계가 있다. 특성이 많은 데이터일수록 정확도가 떨어질 수밖에 없는 단점을 가지게 된다. 그래서 나온 것이 딥러닝이다. 사람이 전처리해주지 않고 컴퓨터가 알아서 하기 때문에 전처리하는 작업에서 시간이 오래 걸린다는 단점이 있지만, 파라미터의 한계를 수많은 반복을 통해 극복하여 사람이 찾지 못하는 특성을 찾아낼 수 있다는 장점을 가지고 있다.
대신에 딥러닝은 편향된 데이터가 나올 가능성이 높다. 딥러닝은 데이터만 많이 몰아서 준다면 컴퓨터가 직접 하기 때문에 편리하지만 편향된 데이터를 넘겨주면 잘못된 판단을 할 수 있으므로 기준을 잡는 데이터들의 라벨값 수를 유사하게 맞춰주는 것이 좋다. 사람이 직접 라벨링을 해주는 머신러닝의 경우 편향될 수 있는 데이터는 전처리과정에서 미리 걸러주기 때문에 그런 문제가 발생하지 않지만 딥러닝의 경우 사람이 해주는 과정을 기계가 직접 하다보니 오히려 잘 걸러지지 못해 편향된 결과가 나오게 될 수 있는 것이다.
딥러닝이 더 좋다, 머신러닝이 더 좋다. 이렇게 나눌 수는 없다. 어떤 데이터를 처리하느냐에 따라 알맞은 처리방법이 다르기 때문이다.

딥러닝의 성공 요인
(1) 비지도 학습을 이용한 전처리
- 군집(Clustering)을 이용한 전처리로 잡음 제거하여 인공신경망 최적화 가능 (제프리 힌튼, 2006)
(2) CNN의 진화
- 예측에 의해 뽑히던 feature들을 기계학습을 이용해 뽑는다는 것
- 고정되어 있는 이미지 등을 주로 처리한다.
- CNN과 RNN은 컴퓨터에게 전처리를 맡겨서 전처리한 내용을 신경망에 넣어주는 역할을 한다.
(3) RNN
- 시간에 따라 계속 들어오는 주식이나 환율 등의 데이터를 전처리하기 위해 나옴
- 시계열 데이터 (Time series data) 에서 탁월한 성능을 보이는 RNN → 가장 깊은 층을 가짐
- LSTM을 게이트 유닛마다 배치하여 Vanishing Gradient 문제 해결
(4) GPU 병렬 컴퓨팅의 등장과 학습 방법의 진화
- GPGPU(General Purpose computing on Graphics Processing Units) 의 개념 개발 (병렬처리)
- 비선형 변환에 쓰이는 Rectified Linear Unit(ReLU)의 개발 - 기울기가 사라지는 문제 해결
- 거대 망을 선택적으로 학습하는 드롭아웃(Dropout)의 발견 - 과적합 문제를 해결
현재 이러한 이유로 성공가능성이 높은 방법에 딥러닝이 많이 거론되고 있다. 하지만 무조건 성공적일 수는 없는 것이 바로 편향된 데이터가 들어가면 잘못된 결과를 낳는다는 그 단점 때문에 열심히 뽑은 데이터도 테스트 단계를 거치다보면 어쩔 수 없이 전량 폐기해야하는 경우가 생기게 된다. 우버 택시가 바로 대표적인 예인데, 택시기사로 오래 일한 분의 데이터를 학습시켰더니 밤 12시가 넘으면 빨간 신호를 모두 무시하고 달리는 등의 문제점이 발생했다. 사람이 전처리를 해주었다면 이 데이터 안에 있는 윤리성이나 법에 어긋난 부분은 걸러주었겠지만 컴퓨터가 직접 전처리과정을 거치고 학습을 하다보니 편향된 데이터로는 걸러줄 수 없는 부분이기 때문에 발생하게 되는 것이다.
딥러닝 프레임워크

tensorflow나 keras는 전문가가 아니어도 사용이 가능하게 되어있다면 파이터치?의 경우 전문가라면 세밀한 부분을 만질 수 있도록 되어있다보니 많은 이들이 성능이 뛰어한 형태의 모델이라고 추천하는 것을 구글링을 하면 볼 수 있다.
Tensorflow
- 구글이 2015년 오픈 소스로 공개한 프레임워크
- 구글 거의 모든 제품에 적용, 다양한 언어 지원, 폭넓은 사용자층 → 가장 널리 사용
- 알파고의 AI 연산 가속기 TPU 에도 적용
- 주요 개발 언어 : Python
- 단점 : GPU 버전은 리눅스만 지원, 다소 느림
Keras
- 파이썬으로 작성된 오픈소스 신경망 프레임워크
- 비전문가도 쉽게 사용할 수 있음
- 실제로 Keras에서는 다양한 뉴럴 네트워크 모델을 미리 지원해주고 있으므로, 그냥 블록을 조립하듯이 네트워크를 만들면 되는 식이라, 전반적인 네트워크 구조를 생각하고 작성한다면 빠른 시간내에 코딩을 할 수 있는 엄청난 장점
- 현재는 tensorflow 위에서 keras가 동작하도록 설계되어 있고, 하위 모듈로 구현되어 있음

Pytorch
- 페이스북 인공지능 연구팀이 만든 파이썬 기반 오픈소스 머신러닝 프레임워크
- 파이토치는 절차가 간단하고 그래프가 동적으로 변화할 수 있음
- 코드 자체도 파이썬과 유사해 진입 장벽이 낮은 편
- 텐서플로우에 비해 사용자층이 얕고 관련 자료를 구하기 어려움
이외 여러가지가 있는데 이것은 학원에서 제공해준 pdf를 캡쳐떠서 기록.



캡처로 제공한 내용인 3가지는 많이 쓰이지 않는 편이다.


출력 노드 수(units)는 마음대로 작성하면 되고 input_dim(입력 노드 수)은 특성 수를 그대로, Activation은 특성에 따라 다르게 이진 분류이면 sigmoid, 다중분류면 softmax, 은닉층처럼 다음층에 값을 그대로 넘겨줘야 한다면 relu를 사용하면 된다. 은닉층은 손깍지 끼듯이 자동으로 연결되어가므로 input_dim을 따로 직접 입력해주지 않아도 값이 자동으로 따라간다.
활성화함수로 sigmoid를 사용하면 입력값이 들어갈 때 sigmoid값에서 출력이 나오는데 1이 들어가서 0.8이 나오게 된다면 sigmoid는 0.8로 나오게 된다. relu는 입력값이 0보다 크면 입력값에 1을 곱해서 그대로 꺼내주고, 입력값이 0보다 작으면 0으로 출력한다. relu는 1을 곱해주기 때문에 값이 작아지지 않지만 sigmoid는 나온 값이 실수이면 실수를 그대로 곱해주기 때문에 값이 점점 작아지게 되어 0이 되버리는 문제가 발생할 수 있다. 이런 문제로 값을 그대로 넘겨줘야 하는 경우에는 sigmoid가 아닌 relu를 사용하게 되었다. 고로 출력을 해야하는 제일 마지막층이 아닌 이상 중간층은 전부 relu, 마지막은 sigmoid나 softmax를 사용한다.

sigmoid는 하나로 나온 값을 2가지로 분류하는 형태라면 회귀모델은 따로 분류할 필요가 없이 값을 그대로 꺼내면 되므로 metrics(평가도구)를 작성하지 않는다. 이진 분류는 알고 있는 것처럼 0보다 큰 값, 0보다 작은 값으로 분류하여 0과 1로 꺼내기 위해 활성화함수를 사용한다. 그런데 만약 값이 0~9처럼 10개의 값이 나온다면? y0~y9까지 컬럼을 만들어야할 것이다. 이 때 사용하는 방법은 원핫인코딩이다. 이렇게 되면 10개의 출력층을 만들어야 하므로 softmax를 사용한다. softmax의 장점은 output이 2개로 0.6과 0.4일 때 결과를 더 큰 값인 0.6으로 출력해준다. 같은 방식으로 결과가 99.9와 0.000…1이 나온다면 99.9가 나올 확률값을 구할 수도 있다.
model4 = Sequential()
# 입력층
# 사용하는 방법은 2가지이다. 하지만 주로 주석처리가 되지 않은 방법을 많이 사용한다.
# model4.add(Dense(units=2, input_dim=2))
# model4.add(Activation("sigmoid"))
model4.add(Dense(2, input_dim=2, activation="relu"))
# 앞으로는 위와 같이 한 층으로 activation까지 작성하는 방법을 사용하도록 한다.
# model4.add(Dense(units=1))
# model4.add(Activation("sigmoid"))
model4.add(Dense(1, activation="relu"))
# 출력층
model4.add(Dense(1, activation="sigmoid"))
model4.summary()
은닉층을 추가해보도록 한다.
model4 = Sequential()
# 입력층 (데이터를 입력받는 역할)
# 사용하는 방법은 2가지이다. 하지만 주로 주석처리가 되지 않은 방법을 많이 사용한다.
# model4.add(Dense(units=2, input_dim=2))
# model4.add(Activation("sigmoid"))
model4.add(Dense(4, input_dim=2, activation="relu"))
# 앞으로는 위와 같이 한 층으로 activation까지 작성하는 방법을 사용하도록 한다.
# model4.add(Dense(units=1))
# model4.add(Activation("sigmoid"))
# 은닉층 (특성을 추출하는 역할)
model4.add(Dense(2, activation="relu"))
# 출력층 (학습된 결과를 출력하는 역할)
model4.add(Dense(1, activation="sigmoid"))
model4.summary()out :

파라미터가 25개가 나오는 것에 대한 설명 ↓

model4.compile(loss="binary_crossentropy", optimizer="adam", metrics=["acc"])
model4.fit(x=X_xor, y=y_xor, epochs=500, batch_size=4)

학습이 제대로 되지 않는 문제 발생...
일단은 설명을 이어간다.




batch_size의 경우 무작정 늘릴 수 없다. 너무 크게 되면 메모리를 그만큼 많이 잡아먹어서 속도가 느려진다. 메모리를 생각하면서 batch_size를 적당히 조절해가며 사용하는 것이 좋다.
읽어보면 좋을 내용은 그룹사진으로 올린다.



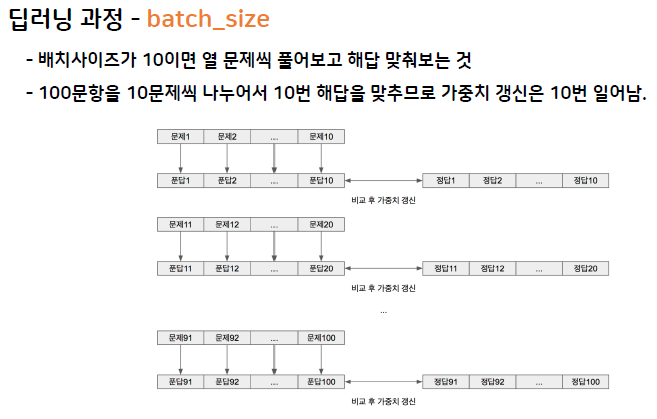


epochs
Q. 모의고사 1회분을 20번 푸는 것과 서로 다른 모의고사 20회분을 1번 푸는 것과는 어떤 차이가 있을까요?
- 분야에 따라 데이터특성에 따라 다를 것
- 잡다한 문제를 많이 푸는 것보다 양질의 문제를 여러 번 푸는 것이 도움
- 현실적으로 데이터를 구하기가 쉽지 않기 때문에 제한된 데이터셋으로 반복적으로 학습하는 것이 효율적
- 결국 epochs는 경험에 따라 각각 정하게 된다.
Q. epochs를 무조건 늘리면 좋을까요?
- 하나의 문제집만 계속 학습하면 오히려 역효과가 발생
- 피아노 칠 때 처음에 곡을 연습할 때는 악보를 보면서 치다가 다음엔 악보 안 보고도 치고, 나중엔 눈 감고도 침
- 하지만 다른 곡은 ? → 오버피팅 (overfitting)
- 악보보고 잘 치는 정도에서 그만 연습하는 것이 좋음
- 실제로 모델을 학습할 때도 오버피팅이 일어나는 지 체크하다가 조짐이 보이면 학습을 중단
학습과정(fit())을 직접 구현해보자
- (1) 파라미터(w, b)들을 초기화 (랜덤)
- (2) 데이터 입력
- (3) 추론(예측값을 구함) : x * w + b -> y'
- (4) 오차 : e = y(실제값) - y'(예측값)
- (5) 오차에 대해 예측값으로 미분(기울기)
- (6) 오차 역전파 : 기울기 값을 기존 파라미터에 더해준다.
- → 가중치 갱신 (학습)
- 기울기를 그대로 더해주면 파라미터 값이 크게 변함
- → 기울기에 일정 비율만큼만 더해준다. (학습률)
- (7) epochs만큼 (2)~(6)번을 반복
# 퍼셉트론 1개로 구성된 신경망
# 넘파이 임포트 안했다면 해줄것
# (특성 데이터, 라벨 데이터, 반복수, 학습률)
def fit_new(X, y, epochs, lr) :
# (1) 파라미터 초기화(w,b)
w = np.random.rand(1)
b = np.random.rand(1)
# epochs만큼 반복해서 학습
for i in range(epochs):
# (3) 입력받는 X를 이용해서 y를 예측
pred_y = w * X + b
# (4) 오차 계산
error = y - pred_y
print("반복수 : {}, 예측값 : {}, 오차 : {}".format(i, pred_y, error))
# (5) 기울기 계산 (비용함수)
d1 = error / pred_y
# (6) 기울기를 이용해서 w, b를 갱신
# 기울기에 일부 비율만큼만 적용되도록 학습률 곱함
w = w + d1 * lr
b = b + d1 * lrout :



내가 목적으로 하는 y값에 따라 예측값이 점점 1에 가깝게 수렴하는 것을 볼 수 있다. 학습률을 작게 주면 조금씩 바뀌면서 학습이 되고, 크게 주면 값이 크게크게 바뀌면서 학습될 것이다.
끝!!
'K-디지털 빅데이터 분석서비스 개발자과정 20.11.02~21.04.12 > PYTHON(웹크롤링, 머신·딥러닝)' 카테고리의 다른 글
| 21.03.02. 딥러닝 - (0) | 2021.03.03 |
|---|---|
| 21.02.17. 딥러닝 - (0) | 2021.02.17 |
| 21.02.15. 딥러닝 - 주피터 노트북 환경설정, 이론(뉴런, 시냅스, …), AND·OR·XOR논리 (0) | 2021.02.15 |
| 21.01.14. 머신러닝 - 텍스트마이닝 두 번째 시간 (0) | 2021.01.14 |
| 21.01.12. 머신러닝 - Decision Tree, Bagging, Random Forest, Boosting (0) | 2021.01.12 |



