

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- 3000 port kill
- 오블완
- window netstat time wait 제거
- conda base 기본 설정
- 실행중인 포트 죽이기
- time wait port kill
- conda 기초 설정
- conda 가상환경 설정 오류
- 려려
- 티스토리챌린지
- conda base 활성화
- Today
- Total
모도리는 공부중
20.11.12. 오전 - 데이터베이스 본문
뷰 라는 객체를 배워봅시다.
vol2, p15
11장. 뷰 생성
p17
뷰 - 논리적으로 하나 이상의 테이블에 있는 데이터의 부분 집합을 나타냅니다.
보안적 측면과 굉장히 밀접한 연관이 있는 객체.
p19
실습을 통해 사용 목적 확인하겠습니다.
p20
하나의 테이블에서 테이블 변경 없이 그대로 보여주는 것 - 단순 뷰
두개 이상의 테이블이나 변형된 값을 보여주는, 변형이 되는 뷰 - 복합뷰
구분해서 볼 필요는 없다. 사용되는 명령어가 달라지거나 그러지 않으므로.
p22
뷰는 as 서브쿼리를 이용해서 생성이 된다.
생성해봅시다.
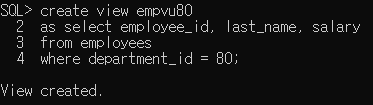
잘 생성됐는지 확인해볼까요?
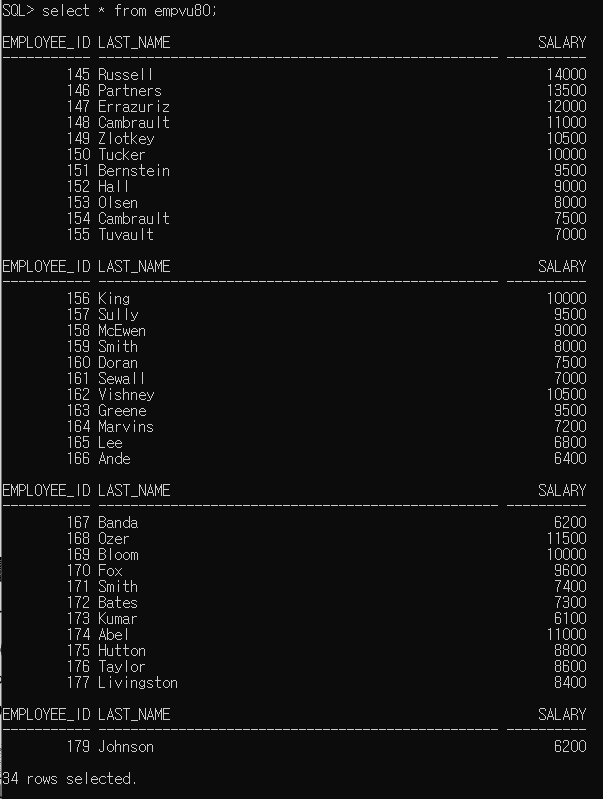
p23
열 별칭을 사용해서 만들어보자.
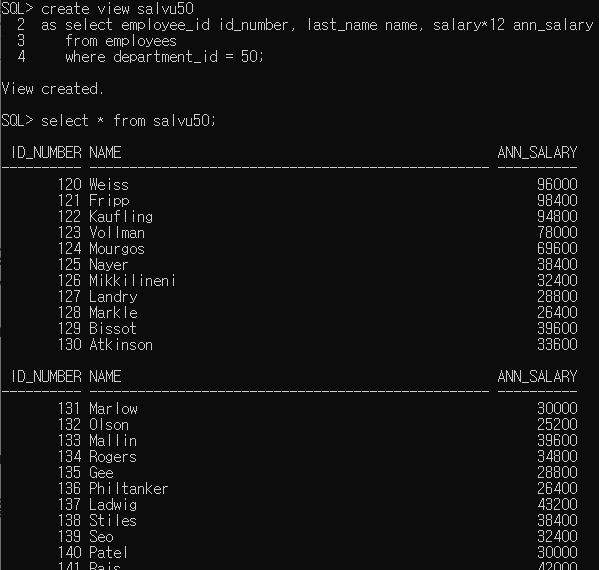
어제 배운 복사된 테이블은 독립된 테이블이므로 원테이블이 변경되어도 그 값이 적용되지 않았지만,
view는 그 값이 적용된다.
p25
view를 다른말로 논리테이블, 가짜테이블 이라고 부른다.
table 생성시,
1. 물리적인구조(저장공간할당)
2. 실제 data저장
3. 데이터딕셔너리(dd)에 구조, 제조, data를 모두 저장
view 생성시,
1. 실제 물리적인 구조를 가지지 않아 따로 저장공간 할당x
2. data를 저장하지 않는다는 말
3. 데이터딕셔너리에 뷰 생성시 사용한 select 서브쿼리 문장텍스트 자체를 저장
└ 사용자들은 테이블인줄 알지, 뷰라는걸 알지 못한다.
p26
구조가 없기 때문에 alter 뷰를 사용하지 않는다.
뷰를 똑같이 해놓고 덮어써버리는 방식으로 수정함으로써 변경된 것처럼 보이게 하는것.
create or replace view를 사용해서 할 수 있음.
p27
결론적으로 셀렉절과 똑같은 것이 뷰이다.
뷰를 사용하지 않으면 항상 셀렉절 밑으로부터 있는 질의를 직접 입력해서 조회해야하지만,
뷰를 생성하면 앞으로 이 복잡한 질의를 쓰지 않고도 단순하게 확인이 가능하다.
그럼 성능적인 측면으로 이놈은 좋은놈일까, 안좋은놈일까?
└ 뷰 실행시 안에 있는 문장이 실제로 재실행이 되기 때문에 파싱현상과 데이터를 불러오는 불편함 때문에 성능은 떨어질 수밖에 없다. 그래서 코드규약을 만들어놓는 것이 좋다. 뷰는 무분별하게 만드는 것이 아닌 자주 사용하는 데이터확인을 위해 만드는 것이 뷰이므로, 뷰에 대한 쿼리문장을 동일하게 만들어놓으면 메모리에 저장되어 있어서 성능적인 측면에서 그렇게까지 나쁘지 않다. 자주 검색을 하면 할수록 메모리에 저장되어있을 확률이 높다는 것.
p28
뷰에 dml작업을 수행하면 원본에도 작업이 이루어진다. ← 단순 뷰일때만 가능.
empvu80은 단순뷰이기 때문에 dml연산을 수행하면 작업이 되지만 그 다음에 만든건 x
view는 액세스 제한을 목적으로 보안을 위해서 사용하는데 dml을 사용한다? 굳이 쓰지 않습니다.
이 뒤 내용은 잠 안오시면 보세요 ㅋㅋ
p34
뷰 제거. 뷰는 테이블을 근간으로 만들긴 했지만 테이블에 어떤 영향을 주는 형태가 아니므로 ..
특정목적을 위해 만들어지는 것이 뷰.
p35
from절에서 사용되는 서브쿼리를 인라인뷰라고 부른다.
셀렉리스트절과 프럼절에서 주로 사용된다. 이 기능이 엄청난 기능을 제공하는데, 많이 어렵다.
문장이 실행되는 동안 테이블처럼 사용되더라~.
p36
우리가 사용할 수 있는 것은 바로 이것.
rownum(로우넘버)는 값을 미리 저장해놓는게 아니라 행이 출력이 되면 그 값을 리턴해준다. 출력이 되지 않은 5번은 돌려줄 수 없는 값인거지.
깜짝문제 - 우리 회사 사람중에 급여를 조금 받는 3사람을 찾으시오
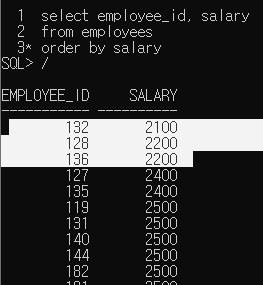
이렇게 3사람을 찾으라는 소리잖아.
그럼 로우넘버 조건을 걸고 해볼까?

우리가 원하는 결과값이 나오지 않는다. 왜??
where절이 먼저 실행되기 때문에 먼저 rownum을 실행해서 상위데이터를 뽑은 다음에 order by로 정렬을 했으니 내가 원하는 값이 나오질 않는것이다.
원하는 형태로 rownum을 제어하려면 어떻게 해야하는가? 순서가 바뀌어야한다. 먼저 정렬을 시키고 상위3개를 뽑으면 되니까!
인라인뷰 - 정렬이 된 값을 먼저 뽑아내기 위해 사용.

우리가 참조하는 테이블은 employees가 아니고 인라인뷰이다..

Q. 부서별 평균급여가 높은 상위 3개의 부서번호와 평균급여를 출력하시오.




이 문장이 실행되면 인라인뷰의 실행결과를 테이블로 사용한다.
그렇기 때문에 avg(salary)라는 컬럼이 문제를 일으킨다.
└ avg(avg(salary))로 쓰면 안돼? → 안돼. 그것도 다 연산으로 인식한단 말야.
통계 관련된 정보를 볼때 뷰를 굉장히 많이 사용한다.
p43
12장. 기타 데이터베이스의 객체
p46
시퀀스는 번호 생성기다. 요청을 하면 그 때마다 번호를 생성해서 리턴해주는데, 그냥 막 생성해주는 것이 아닌 중복되지 않은 고유한 번호를 자동으로 생성해주는 역할을 한다. 이 시퀀스는 공유가 가능하다. 중복이 되지 않다보니 프라이머리키를 사용할 때 이 시퀀스를 많이 사용한다. 숫자값의 일련번호들을 프라이머리키로 지정하는 경우에 시퀀스를 꽤 자주 사용한다.
시퀀스를 메모리에 캐시를 하면 액세스효율이 높아진다. → 캐시가 뭔데요?
메모리 : 공간이 부족하면 먼저 들어온 것들 중에 안 쓰는걸 먼저 빼버린다.
메모리 캐시? : 디폴트로 20개의 시퀀스 번호를 생성해서 메모리에 고정. 요청시 이미 저장되어있는 번호를 돌려준다. 다 사용했다? 그러면 시퀀스가 자동으로 20개를 또 생성해서 메모리에 저장을 해둔다. 이것은 돈지랄 가능한 회사들이 사용. 왜? 그만큼 작업에 필요한 메모리 공간을 딱 시퀀스가 캐시해버리면 그만큼의 공간을 사용할 수 없다보니 다른 작업들의 성능이 떨어지는 아이러니한 현상이 일어날 수 있다.
실제 현업에서는 시퀀스가 아닌 셀렉절에서 메모리캐시기능을 꽤 자주 사용한다. (성능적인 측면에서 좋아서.)
메모리는 주 메모리와 보조 메모리로 구분이 된다. 보조 메모리는 메모리가 공간이 부족할 때 디스크 공간을 일부 할당받아서 그 공간을 메모리처럼 사용할 수 있도록하는 것을 보조 메모리라고 한다. (컴활이랑 워드 공부할 때 생각나네 ㅋ.ㅋ)
정렬을 사용하면 정렬되지 않은 값을 일단 메모리에 불러들인다. 그리고 똑같은 공간을 곱하기2만큼의 공간을 불러와서 거기에서 정렬을 해준다. 이처럼 매번 곱하기2만큼의 공간을 사용한다는 뜻.
테이블에는 정렬되지 않은 데이터가 저장되어 있는 것이지, 정렬된 데이터가 저장된 것이 아니다보니 매번 사용할 때마다 메모리를 사용하게 됨으로써 그만큼 공간을 못 쓰는 거죠.
오라클에서 솔트 에어리어(sort_area)라는 정렬 전용 공간을 따로 지정해놓고 사용한다. 사이즈를 키워주지 못한다.
정렬된 결과를 필요한 공간만큼 디스크로 보내고 또 정렬된 것을 보내서 이것들을 병합해준다.
정렬할때마다 공간을 할당하고, 끝나면 다시 디스크로 반납~ 이러니 i/o가 엄청 늘어나겠죠? 그러니 정렬작업을 되도록 피하는 게 좋다.
아니 그럼, 정렬이 너무 싫은건데.. 테이블이 그냥 정리되어 있으면 안돼?
응 안돼. 정렬이 되어있으면 select 범위검색이나 정렬검색을 할 때는 매~우 좋지. 하.지.만, @@@!@#$!##@(타이핑하다 놓친 부분 ㅋㅋㅋ 아마도 데이터수정작업이 이뤄지면을 말하는 것 같다.) dbms가 틀어지니 다시 재구축해야겠죠?
자... 다시 본론으로 돌아와서 ㅋㅋㅋㅋㅋㅋㅋ
시퀀스!
p48
increment by는 증가값
strat with 처음 생성 값
maxvalue 최대 생성될 값(넘버입니다. 갯수 아니고.) ← 도달시 더이상 생성 x
default가 노캐시.
nocycle은 맥스밸류에 다다르면 더이상 사용할 수 없다는 뜻. ← 프라이머리키에 사용될수록 cycle옵션 주지 않음.
현재 예제에 있는 번호 120은 중복이 일어나게 되므로 300번으로 바꿔서 실행해봅시다.

p50
nextval은 시퀀스에서 값을 요청해 추출하는 역할을 한다.
여기서 추출된 시퀀스 넘버가 currval에 저장된다. rownum과 비슷하죠?
p52



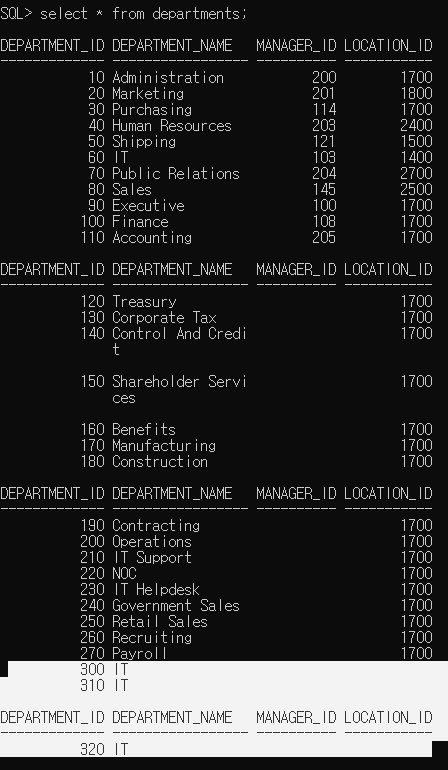
이런식으로 사용한다~ 이겁니다. 이제 rollback해볼까요?

rollback을 수행 후 다시 같은 작업을 수행하면 몇번이 들어가게 될까요?
300번이다? 330번이다?
330번이 정답!

시퀀스는 값을 추출하는 역할을 하는거지, 추출된 값의 상태를 신경쓰지 않는다.
고로, 한 번 추출된 값을 다시 추출하지 않는다.
시퀀스는 데이터를 가지고 있지 않고 숫자를 생성해주는 역할밖에 없기 때문에 보안적인 측면에서 전혀 상관이 없다. 그런 관계로 공유가 가능하다. 시퀀스의 특성 2가지 때문에 갭이 발생한다.
| A | B |
| 300 | 320 |
| 310 | 330 |
| 340 |
이런식으로 310과 340 사이에 갭이 생기게 된다. 훅~ 건너뛰는거지.
세이브포인트라는 내부 기능이 생겼다.
문장마다 (명령문마다) 세이브포인트를 발생시켜서 트랜잭션이 아예 초기화되는 현상을 방지해준다.
(옛날엔.. .오타 하나 있으면 죄다 날라갔어.... 세상에 소름이잖아?)
시퀀스 이름을 다른 사용자에게 안 알려주는게.. 가장 근본적으로 좋은 방법이겠죠..?
p54
startwith는 절대로 변경할 수가 없다. 왜?
이미 추출된 번호가 있기 때문에 중복이 일어나거나 필요없는 이전 번호가 생길 수 있으므로 절대 수정할 수 없다.
└ 바꾸고 싶으면? 현재 시퀀스 지우고 재생성하는 경우만 startwith를 바꿀 수 있다.
increment by는 10이든 20이든 언제든지 바꿀 수 있다.
maxvalue는 늘리는건 얼마든지 가능하나 줄이는건 검증이 필요하다. 아직 생성되지 않은 경우 바꿀 수 있으나 이미 생성된 경우 바꾸고자 하면 안되므로 검증단계를 거쳐서 확인하고 줄이는 것이다.
p55
읽어보시고.. (내가 못들음ㅋㅋ)
p56
전혀 상관이 없다! 영향을 미치지 않아요~
p57
인덱스!!
테이블 전체에 설치하지 않고 제약조건처럼 고유한 컬럼단위로 인덱스를 설치한다.
인덱스는 배열의 구조형태를 가지고 있다.
이렇게 생겼다..

인덱스는 값을 정렬해서 저장한다. 오른쪽엔 포인터라는 녀석을 저장하는데 포인터는 주소! 행이 저장되어있는 실제 주소값을 오른쪽에 저장해서 연결해준다..
중복이 안되어있는 값의 인덱스를 쓰는게 좋다. 그리고 범위 검색에 효율적이다.
그럼, 모든 컬럼에 인덱스 부여하면 검색속도 빨라지지 않을까요? nope! 무분별하게 사용하면 최악의 검색속도를 자랑하게 한다. 기본적으로 내가 접근해야할 물리적인 구조가 인덱스는 많다. 그래서 실제 전체에서 5~15%의 값을 검색할 때 매우 효율적이며 그 이상의 값을 검색한다면 테이블풀스캔으로 찾는게 더 빠르다.
p71
13장 사용자 액세스 제어
디비에 접근하는 사용자들에게 권한을 가지고 사용하는 언어다..?
p73
일반사용자는 접근할 수 없다.
p74
크게 두가지로 나눠서 관리한다.
시스템권한 : 디비 전반적인 것을 컨트롤
객체 권한 : 객체 자체에 액세스해서 객체를 조작할 수 있는 권한
p75
이것 외에도 수많은 권한들이 실제로 존재한다.
시스템권한은 안 외워도 된다. any라는 단어가 들어가있으면 모든 테이블을 관리할 수 있는 권한이라고 생각하자.
p76
DBA 생성할 때..
1. user생성( id/pw 지정) / 삭제
2. user에게 권한 부여 / 회수
같이 실습합시다.
sql창을 하나 더 띄워주세요~
sysdba → bavk
sysopper → x
syslem → DBA
sql에서 해야하는데 뭐가 또 생성이 안돼서 일단 메모장에 한 것 먼저 캡쳐.


방금까지 user했구요, scott? 초반에 쓰던것이며 지금은 hr이라는 명령어로 다 바뀌어 있다.
p78
가볍게 읽고 해석만 해도 되겠습니다.
p79
카카오 이용자들을 아이디를 다 기억해? 아니잖아. 어떻게 효율적으로 관리할까요.
롤 : 권한을 모아놓은 집합.
create role이라는 명령어로 집합 생성 후 권한 부여
| 1. create role manager; 2. grant A,B to manager; 3. grant manager to test, test1; 4. grant C,D to manager; 5. revoke A from manager; |
 |
현업에서는 업무별로 롤을 다 할당하고, 그 직원들에게 해당 롤만 부여해주면 되기 때문에 실제로 잘 사용하며 대부분의 관리를 진행한다.
시스템권한은 일반사용자들이
객체 권한은 특정 유저(모든 권한을 다 가지고 있어야함)가 사용하는 객체를 다른 유저가 사용할 수 있도록.
p82
프로시저가 뭘하는지 개념만 아셔도 됩니다.
이론 주관식 50%
SQL 적는것 50%
재시험은 꽤 어렵게 나올겁니다. 그러니 시험공부 제대로 하세요.
p84
객체권한 이렇게 주는거구나~ 정도만 아셔도 됩니다.
p85
기본적으로 권한 부여는 dba만 가능하지만 with grant option를 사용하면 유저가 자신에게 할당된 권한 안에서 또 다른 유저에게 부여해줄 수 있다. with abmin option도 마찬가지.
└ 시험용으로 꼭 알아두세요 ㅋㅋㅋㅋ (강조강조또강조)
시스템권한은 종속적인 관계를 연결하지 않아서 회수는 dba가 직접 해야한다.
p86
딕셔너리~
p87
revoke~
p89는 자사 프로그램 홍보 ㅋㅋㅋ (모든 책들이 그렇답니다.)
dbl이나 dml은 손을 놓아도 되지만 select절은 꼭.... 손 놓지 마세요.
좀 더 관심 있는 사람은 2권 13장쪽부터 연습문제 보면서 직접 공부하며 준비해보세요~ 어려우면 도와드릴게요.
'K-디지털 빅데이터 분석서비스 개발자과정 20.11.02~21.04.12 > SQL' 카테고리의 다른 글
| 20.11.11. 오전 - 데이터베이스 (0) | 2020.11.11 |
|---|---|
| 20.11.10. 오후 - 데이터베이스 연습문제, DDL, DCL (0) | 2020.11.10 |
| 20.11.09. 오전 - 데이터베이스 연습문제 & 서브쿼리 (0) | 2020.11.09 |
| 20.11.06. 오전 - 데이터베이스 join, having, group by, 그룹함수 (0) | 2020.11.06 |
| 20.11.05. 오전 - 데이터베이스 where절 활용 및 연습문제 (0) | 2020.11.05 |



